Introduction
In our society presently, immunoassay techniques used in data analyses have assumed a place of high significance, particularly as it is applicable to pure/applied researches; where the techniques are adopted for such developments as ultrasensitive immunoassays in antigenic and antibody analyses. Ultrasensitive/rapid enzyme immunoassays, have presented more current, flexible, and indeed expressive information that is considerably more applicable to scientific studies (Huston, D.P, et al., 1991). This experiment presents an experiment using data mining in the development of ELISAs
Aim of the Experiment
The aim of this experiment is to utilize knowledge and principles of data mining in depicting the investigation of emergent, easier understood, more fascinating, better-to-use, practicable, and appropriately patterned voluminous data in biology- particularly on development of ELISAs
Method
Data mining as applied to this ELISA studies is a one-stop point for the unification of a number of disciplines including, parallel/distribution processes, visualizations, artificial-intelligence, machine-learning, as well as statistics. It could also be seen as a process involving the review of a pattern, an association, an anomaly, and a statistically relevant structure. The significance of this important tool in aiding knowledge-based discoveries, realization of emergent phenomenal, and enhancing the general understanding of analytical situations is tremendous. This is particularly achieved through recognition of patterns and discovering identified characterizations in imagery and high-dimension data. A pattern could be said to be the organizational structuring of data.
Results
The figure below identifies the behaviour of an assay under investigation through immunoassay as it has been analyzed through data mining. The experiment illustrates that significance of adapting to the application of data-mining techniques for simulation experiments/observations in varying domains of sciences. This is because simulation is known to be highly effective in visual expressions through the presentation of models as against the non pictorial aspect of non-simulated experiments.
It is figured that the possible error for the analyzed result is placed at -0.75% which reflects a standard deviational percentage error at 8.58%. To actualize accurate results, there was a testing of the assay through assaying the concentration with serum and an addition of diluted anti-human igG antibody. However, there were no noticeable inferences from the antibio 50ul of 2m.
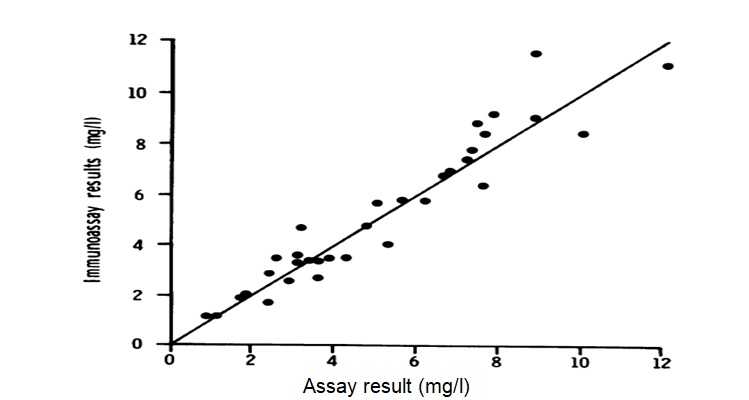
The experiment further demonstrates the vitality of simulation in aiding researches realize more visual outcomes. Particularly, it is realized that most often than not, visualization without a backed up simulation fall to produces satisfying outcomes. Through a well coupled visualized data mined technique, there is the possibility of enhancing interactive displays of the research seeks to explore and generation appropriate outputs. This thus is very helpful particularly for realizing outputs for particularly defined data. Additionally, the simulated data for mining offers a wide variety of options. There is the illustration of actualization of objectivity to analyzed data.
Methods
The mined data was modified completely through the application of XMLA scripts and ran for predicting queries alongside programmed models for applicability. There is also the possibility for the extension of required structural tools, particularly as regarding analyzing of data through decoding based. This experiment employs the usage of enzyme-immunoassay (EIA) as a tool for detecting and quantifying specified antigen-elicited molecules. Even though the tool is most applicable to conducting research or studies on clinical processes such as ones involving cancerous or autoimmune disorders, it is very effective in analyzing biologically based samples like plasma, urine, cell-extracts, or serum
Discussion
There are usually higher possibilities for generating data as compared to the exploring, analyzing or comprehending of the content of the data. Technological innovations have further made easier the possibilities of gathering data particularly from experimental, simulative, or observational events. Quite a number of times, there is much complexity with a given data, however, mining could majorly be time-serial framed, or imagery in nature. For the purpose of generating effective results for this experiment, it was necessary to explore the available data intensively through the extraction of vital information that constituted the data. But be it as it was, the entire volume and the level of complexity of the data made analyzing the content challenging practically. Based on this fact, the readily noticeable benefits of the experiment where a better option for driving the computational gathered data was prefered. Through the application of extended ideas into specified areas that require data mining, it is supposed that the improvement of interaction with multidimensional time-based data is realizable. This is very helpful in identifying the data’s pattern, thereby enabling the possibility for one to dig intensively into a given data.
Where as the problems with dealing with the data in our experiment could be surmounted through the usage of larger data, for an effective result there must be the addressing of added data specifically for scientific purpose. As an illustration, data which is applicable to scientific research is often available in imagery forms; this format is regarded as posing severe challenges particularly for extraction purpose. At a majority of instances, there could be lack of classified information in grouping problems as well as in iterating mined data for processes that could be needed for obtaining appropriate size of trained sets. Quite a number of sensitive and applicable data fusions are usually gathered through diverse resolutions.
The approach used to scale data and patterning it has been through recognized algorithm of multidimensional data address. In particular, the experiment hinges on the following:
- Image processing techniques, including wavelets, for feature extraction;
- Dimension reduction techniques to handle multi-dimensional data;
- Scalable algorithms for classification and clustering;
- Parallel implementations for interactive exploration of data; and
- Applied statistics to ensure that the conclusions drawn from the data are statistically sound (Drossou, V., et al., 1995)
The development of an algorithm for the context of the experiment has been applicable an extendable for the detection of immunoassays. The mined experimental data sheers the limit of the effective bed-test for the purpose of the analysis. These instrumentalities are effective for simulations and for observations.
Conclusion
Data-mining has been known to present impressive opportunities for the interpretation of raw information. Based on the fact that the prediction of outcomes automates processes of generating fresh figures in cumbersome databases, it has become less necessary to institute analytical processes which are traditional in nature. The use of predictive analysis has proven to be quite effective particularly in carrying out predictions that could be used in replacing existent null values that are found in a presented source-data; this is equally of high efficiency in discovering emergent source-data structures. These have been effectively used through the experiment, particularly in the realization of attribute that are cable of influencing key-performance-indicators (KPIs), and in finding useful information on data that could ordinarily be hideous.
Reference List
Drossou, V., et al., 1995. Concentrations of main serum opsonins in early infancy. Arch Dis Child Fetal Neonatal Ed, 72(1), pp.172-F5.
Huston, D.P, et al., 1991. Immunoglobulin deficiency syndromes and therapy. J Allergy Clin Immunol, 87(24), pp.1-17.