Abstract
The garbage collection mechanism for the YAFFS file system incorporates a search strategy defined by the YAFFS garbage collection algorithm, O (K) space [1]. The total number of blocks targeted for sampling to identify the dirtiest block to be erased is algorithmically achieved based on the size of the flash storage, K, though the value of K increases with an increasing number of victim blocks. The running time of the algorithm is characterized by O (K) space [1] of the priority queue. On the other hand, flash memory characteristics influence to a significant extent the read and delete operations thus demanding a continuous update as the victim memory changes based on the O (lg (K)) algorithm. The operating parameters are selected based on the mathematical relation selection strategy for the optimal value of M:
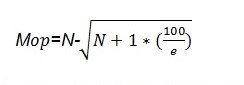
The paper focuses on experimental findings based on sampling performance measures and the factors that affect the overall performance of the YAFFS file system in identifying a block of data to erase.
Summar
Sampling the dirtiest block to be erased is based on an algorithmic strategy for identifying the victim block with useful data to be erased for reuse. Employing a garbage collection mechanism will enable useful data to be copied and stored safely before the erase operation commences to free the target memory space for reuse. Different mechanisms for carrying out the erase operation exist. One such mechanism is to use heuristics to identify and select the target block to be freed of data allowing free space to be created for reuse. An algorithmic approach for carrying out the operation is based on the score count of a block and the priorities associated and provided by the victim algorithm. Typically, the running time of the algorithm is characterized by O (K) space [1] of the priority queue. The size of K varies with varying flash capacities, with higher values of K making the whole operation expensive. The sampling strategy for the dirtiest block to be erased will depend therefore depend on continuous updates defined by the algorithm O (lg (K) operations [1]. The following paper will examine the sampling erase strategies through an experimental setup and a presentation and analysis of the results.
Garbage Collection
The following section details the garbage collection goals with the strategy to reduce the cost of cleaning memory and reducing the level of even outwear, which is a performance-based Sampling mechanism for YAFFS file systems. The blocks of data under examination can be cleaned to provide freed space for reuse. Typically, the cleaning algorithmic strategy for identifying the dirtiest block of data to be erased based on the runtime least-cost algorithm is discussed later in the paper (Ajwani, 11).
Typically, the main aim of the paper is to examine and detail the current algorithmic approaches that use score-based heuristics to identify and select the target memory block to be cleaned and for wear leveling. A typical characteristic of the YAFFS1 file system structure (Neubadt, 5).
In addition to that, the paper aims at selecting a victim block with the highest score based on a number of variables. The variables include metadata formation, the degree of memory block utilization, the erase schedule of the victim block, and the target bock erase counts (Bird,4).
It is therefore important to identify the block to be erased by identifying the victim block objects to be erased, identifying their positions in the block to be erased, and the relationship of the age of the chunk to be cleaned (Cao, 7).
The erase mechanisms and algorithms must be based on the flash memory characteristics summarized below.
Flash Memory Characteristics
From a background point of view, flash memory read and write operational characteristics speeds are equivalent to sequential random access operations. On the other hand, YAFFS1 files are written sequentially and deletion markers are used to bridge the sequential rule. On the other hand, YAFFS2 does not use deletion markers and typically writes data in a sequential manner. In addition to that, during the garbage collection time, the garbage collector must identify chunks that belong to specific objects to be deleted, identify the point in time where the specific chuck resides, and distinguish the position of the chunks by determining its storage age (Surhone et al, 8).
However, the read operation is significantly slower than the write operations. Among the performance distinguishing characteristics of flash memory is that they do not allow memory overwrites and do not overwrite a page that has been written to. An erase operation has to be done before a write operation is done to solve the in place problem. In addition to that, flash memory is characterized by a limited number of reading and write operations that can be performed before any operational failure is experienced (Manning,5).
In a YAFFS1 operating environment, losses that occur due to power failures or system crashes can be recreated and the original state of the YAFFS1 file is therefore restored (Jaegeuk, 18).
The performance of the YAFFS file system is affected by the distribution of the files within the system, the search strategy algorithm, and the stored data characteristics (Man-Keun & Seung-Ho, 22).
Based on the following output from a data sheet showing the output for a read and write operation, it is clear that read and write operations precede each other with the erase operation being more time costly as illustrated below.
A datasheet showing the read and erase operations on a flash memory device.
Noticeably, the write operation changes the state of the memory from 1 to zero. On the other hand, the erase operation changes the state of the memory from zero to one (Neubadt, 21).
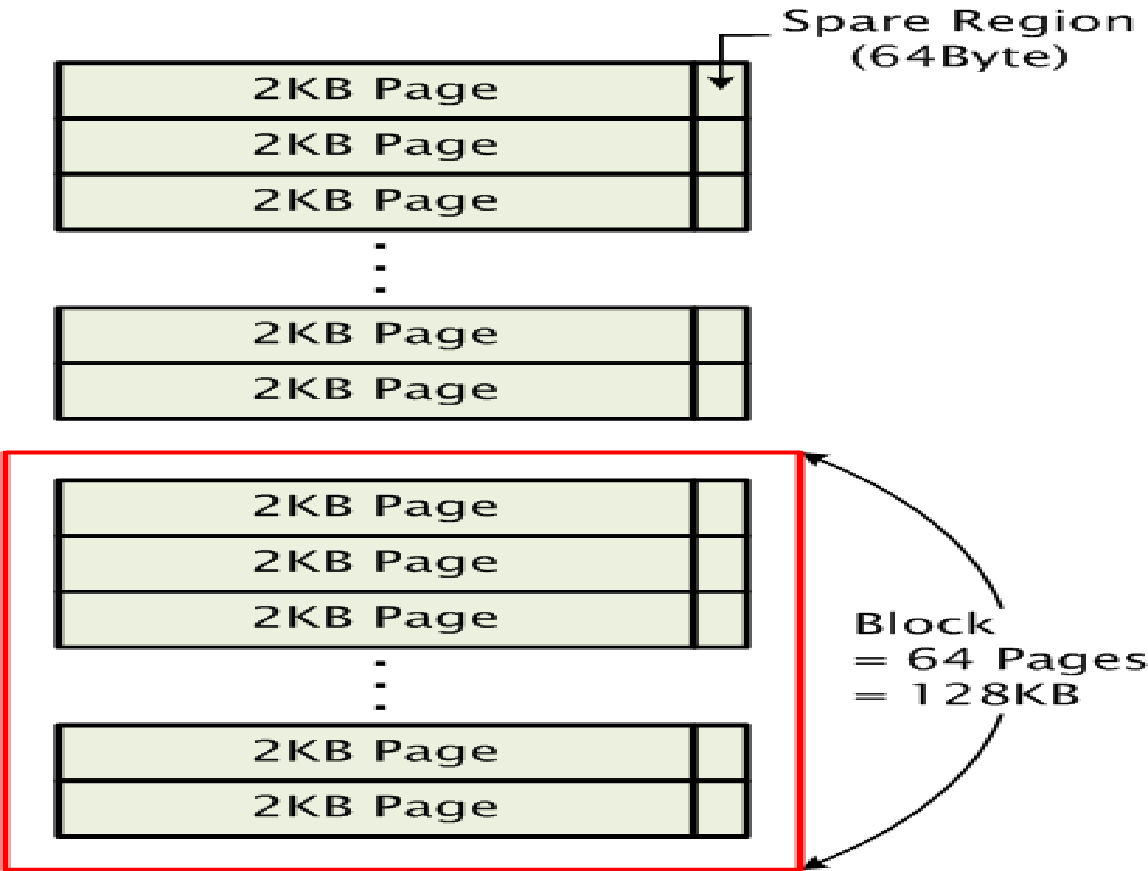
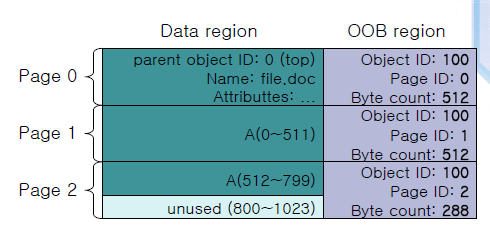
It is important to consider the YAFS file system structure as exemplified in the following illustration. Typically, the log structure of the file influences the seek time when identifying the seek time for the dirtiest block to be erased. The data regions in relation to the object region are related as illustrated in the YAFFS files structure below (Wei & Carl,
22).
Reducing Garbage Collection Metadata
Reducing garbage collection metadata focuses on wear leveling that uses aggregate objects to save the SRAM memory space. All logical blocks of data or objects are put into the same category by maintaining an average erase count for each block. In the scheme, the YAFFS objects require O (K) space for the above operation. On the other hand, the sampling-based strategy uses O (N) space for the SRAM with arbitrary positions for each block as illustrated below.
The number of objects erased in the YAFF file system structure is kept in the record based on calculations of the differences between the least worn count and the least block erase count by the K-leveling algorithm. Thus the K-leveling algorithm is four times more efficient in reducing the size of metadata based on the O (N) space, where N<<K. A comparative analysis of the operational efficiency of the sampling-based algorithm is illustrated below with the sampling-based algorithm detailed later.
Sampling Algorithm 1
The sampling algorithm is explained in the comments below.
Sampling Algorithm Iteration ([0, 1,…N-1])
//Implements a recursive random search strategy
//Input fresh blocks count
//output randomly selected element of the N-M
//sort N elements in ascending order through calculations of the metadata
//Sort and select block count with Max or Min score
//throw the sorted victim block
//sort and throw metadata for N-M-1 blocks in decreasing sequence.
0; ← r ← N-1
while count =0 do
M ← [N-M]
if (N=0) [N-M-1]
return Max, Min
else
return
metadata N-M-1
end while
A recurve evaluation and random selection operation of the target block from a family of N blocks are discriminated based on a calculation of the count policy. The selection policy is based on max and min values thrown from the search. The recursively random search decides the quality of the search algorithm. The actual sample retained after the throw operation due to the discrimination of the entire metadata yields the N-M-1 in a definite order. However, the sampling-based algorithm examined below is better than the current algorithm.
Sampling-Based Algorithm
The pseudo-code for the sampling-based algorithm is illustrated below.
If ( iteration=1) then
N (fresh blocks) ← Random data selection
If (score scores-max) ← throw N-M samples
else
N-M (fresh blocks) ← Random metadata selection
end if
N (sampled blocks) ← calculate metadata
Sort scores ← Descending order
Max (min) scores ← select victim block
Metadata ← remove from victim block
Metadata ← Remove for N-M-1 the last block
A random read operation on the metadata is performed to calculate the scores on the flash memory on the N available blocks. The output scores from the calculation enable sorting of metadata allowing victim blocks with minimum or maximum counts to discriminate samples for selection. Bad blocks defined by N-M are discarded with a low probability for the next section. The victim blocks eviction criteria are used to throw the N-M-1 samples.
A Working Example
Suppose the number of sampled blocks in the SRAM is equivalent to N=5 with a working value of M=2. According to the above algorithm, the number of randomly sampled blocks of data is 5 migrated to the SRAM. Calculated sample score values are used to provide the erase count. O(N- lg(N)) operations are used for the sorting task. The total number of operations based on a minimum erase count is selected, in this case, to be 10. Thus, the selection for O(N-M) + O(N- lg(N)) -O(N)+O(N-lg(N)) -O(N-lg(N)) as exemplified in the calculation N-M-1, equivalent to 5-2-1=2. The findings from the setup are detailed in the analysis section.
Parameter Selection
From the above experimental setting, discarded pages, allocated pages, empty pages, and a full block of data are distinguished. The approach for selecting the victim candidate is based on smaller values of m by identifiably incorporating older blocks and ignoring recently loaded files into memory. The selection strategy for the optimal value of M is mathematically related below:
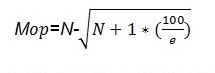
Importantly during the sampling operation, an error is bound to happen by incorporating other objects in the YAFFS file structure system. In addition to that, the number of operations performed on the YAFF objects identified for deletion during the write and read operations are defined in the relation:
N-M
Calculating the value of the score for the objects to be sampled and deleted, the sorting strategy is theoretically and practically based on the O (N -lg (N)) algorithm
Heuristics for Evaluating a Block
The strategy for selecting a block to be erased is based on an algorithmic scheme that uses information about the metadata stored in each block to be evaluated. On the other hand, considering the YAFFS mechanism, an algorithmic approach similar to the algorithm used to identify the block upon which to carry the garbage collection above can be used (Chuanyi, 23). During the search operation, it is important for the search algorithm to maintain a priority queue to reduce the cost of the search time by focusing on the priority score. In the event, the search is not fulfilled or the victim object is not identified the algorithm exits. A priority queue performs the search operation based on the search heuristics examined below (Chang, 34).
It is important to incorporate the amount of space occupied by the priority queue during the search. Within the SRAM, the cost of the space is defined by the algorithm O (K) [1], where K is defined by the size of the flash memory storage which is again defined by the number of memory objects under examination (Gervasi, Gavrilova, 3). On the other hand, there is a linear relationship between K and the flash memory storage size. To carry out the operation, metadata size estimation for 32 KB SRAM for one GB storage is calculated based on the following mathematical relation:
Number of blocks for I GB * metadata size for @ block =metadata size for 1GB. Which is equivalent to 4096*8B=32GB
On the other hand for 1TB,
a number of blocks for I GB * metadata size for @ block =metadata size for 1GB.
Thus, giving the result;
1024*32KB=32 MB.
However, increasing the amount of available space for SRAM to accommodate increasing space occupied by the metadata demands the scaling of queuing operations with O (lg (K)) operations [1] and higher computational loads. Thus, a sampling mechanism to estimate the functionality of the garbage collection algorithms can be used. A sampling-based algorithm will be used in this case to minimize the SRAM demands for space by considering the immediate number of available space (Woodhouse, 2) and (Jones, Hosking & Moss, 18).
The main challenge is to identify the NAND memory metadata to avoid the scalability problem associated with the rising number of objects being stored and the level of memory usage (Youjip, 4).
Experimental Setup
Assume a block contains p number of pages. The victim selection criteria are based on r/ (a*p) number of operations where r is the number of write requests. r/ (a*p)*O(N- lg(N)) are required indicating the number of operations to be efficiently lower.
It is important to use a typical system such as the embedded EVB (SMDK2410) with a processor speed of 200 MHz and the main memory of 64 MBs. The NAND is a Samsung K9S1208VOM SMC card.
On the other hand, the flash memory characteristics of the devices used in the experiment are tabulated below.
Experimental data for the Samsung flash memory device
The aim of the experiment is to identify the dirtiest file to be erased based on the heuristics of the YAFFS garbage collection strategy. YAFFS is a hybrid of the YAFFS1 and YAFFS2 garbage collection mechanisms which integrates both the O (K) [1] algorithm and the O (lg (K)) operations [1] for space and garbage collection operations. Typically, the whole concept is heuristics and is based on the concept of performance-based sampling (Jones & Lins, 9) and (Thwel & Thein,14).
In the experimental setup, we simulate a block of data to be erased based on a sampling algorithm by first creating a block of objects to be erased. The following setup was to identify the read and write operations by establishing the time for executing the operations. In addition to that, hardware capable of 50ns/read and write operations was used and provided for performance overheads that could result from the read and write computations.
Computational time for the read operation
The flash memory access time can be calculated from the above experimental results based on access time.
Results from the experimental run
In the experiment to identify the dirtiest block to be erased in the YAFFS file system, the following strategy is applied (Wilson, 11).
In the experimental setup, a dirty block is selected by an iteration of available objects constituting the chunk to be deleted. The file system has to establish the status of the file before erasing or creating a new copy to allow the original copy to be deleted. In addition to that, a restructuring of the Ram data structure has to be done to reflect any computational operations performed above. Once the data object has been cleaned, the created space is ready for use (Lee, 27).
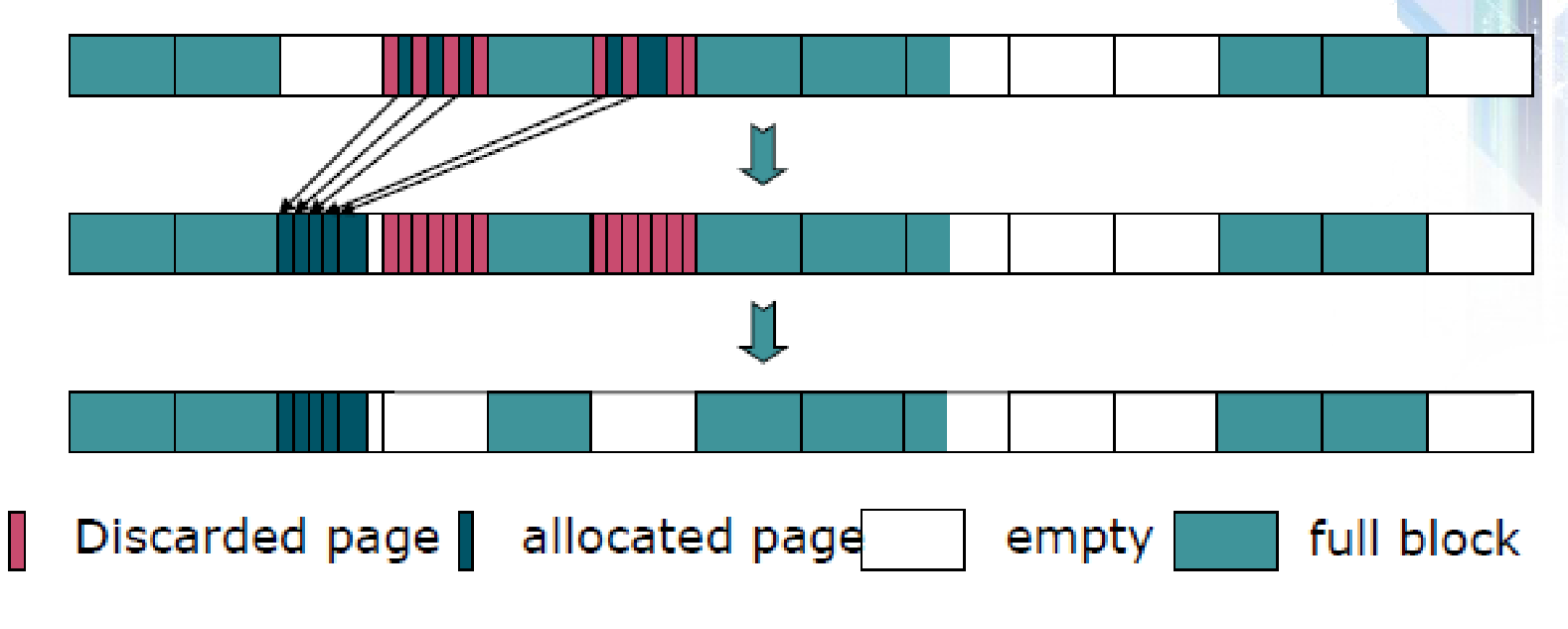
The system performance during the erase operation can be enhanced by using an aggressive garbage collection strategy (Yang, 5).
Results
Based on the above experimental findings, the seek strategy is based on the O (lg (K)) operations [1], and the operations are iteratively performed. In addition to that, heuristics applied on the block during the search operation are based on identifying the dirtiest block to be erased based on the O (N-lg (N)) algorithm. Thus, the number of operations performed in the YAFFS file system in the above setup to be algorithmically defined below.
O (N-lg (N)). Typically, the aggregate value obtained for O (N-lg (N is derivative of sum of O (N – lg (N)), O (N) +O (N-lg (N)), and O (N -M).
Analysis
Analytically, the outcome from the experiment indicates the search strategy to be based on a sampling mechanism that uses O (N) space to store the objects identified in the YAFF file structure. N represents the size of the sample under consideration with the O (lg (K)) operations [1] with storage of the priority queue [1]. Typically, K symbolizes the flash disk storage size as an aggregate of the blocks to be considered as exemplified in the tables above. The value used in the Sampling-based algorithm for N is fixed and less than K.
Analytically, sampled blocks of data for the YAFFS file system structure register higher performance measures. When the sample size is increased or the target block to be erased increases in size, the erase rises.
From the experimental setup section, K increases with an increasing number of samples. On the other hand, experimental results show that N does not seem to vary with K, with the conclusion that the sampling-based algorithm is efficient since it demands fewer SRAM operations.
Works Cited
Ajwani, Daniel, et al. “Characterizing the performance of flash memory storage devices and its impact on algorithm design”. Workshop on Experimental Algorithms (WEA), 5038 (LNCS): 208–219, 2008.
Bird, Thomas “Methods to Improve Bootup Time in Linux,” Proceeding of the Ottawa Linux Symposium (OLS), Sony Electronics, 2004.
Cao, Longbird. et al. Advanced Data Mining and Applications: 6th International Conference. China: Adma Chongqing, 2010.
Chang, Lee. An Adaptive Striping Architecture for Flash Memory Storage Systems of Embedded Systems, CASES, 2007.
Chuanyi, Liu et al. “D.H.C.; Semantic Data De-duplication for archival storage systems” Computer Systems Architecture Conference, ACSAC, 2008.
Gervasi, Osvaldo and Gavrilova, Marina, Computational Science and Its Applications: ICCSA 2007: International Conference, Kuala Lumpur, Malaysia.
Jaegeuk, Kim. et al. “Efficient Metadata Management for Flash File Systems” 11th IEEE Symposium on Object Oriented Real-Time Distributed Computing (ISORC). Ningbo: IEEE, 2009.
Jones, Richard and Lins, Rafael, D. Garbage Collection: Algorithms for Automatic Dynamic Memory Management. New Jersey: Wiley, 1996.
Jones, Richard, Hosking, Antony & Moss, Eliot The Garbage Collection Handbook: The Art of Automatic Memory Management, London: CRC Press, 2001.
Lee, Yann-Hang, Embedded software and systems: third international conference, ICESS 2007, Daegu, Korea, 2007.
Man-Keun Seo & Seung-Ho, Lim. Deduplication flash file system with PRAM for non- linear editing: Consumer Electronics. Ningbo: IEEE, 2010.
Manning, Charles, How YAFFS Works, 2009. Web.
Neubadt, Sam, The Effects on Read Performance from the Addition of a Long Term Read Buffer to YAFFS2, 2009. Web.
Surhone, Lambert. et al. Yaffs, VDM Verlag Dr. Mueller AG & Co. Kg, 2010
Thwel, Ni Lar & Thein Tin. An Efficient Indexing Mechanism for Data Deduplication. Current Trends in Information Technology (CTIT). Ningbo: IEEE, 2009.
Wei, Fu and Carl Hauser, A Real-Time Garbage Collection Framework for Embedded Systems. ACM SCOPES ‘2005.
Wilson, Paul R. “Uniprocessor Garbage Collection Techniques” IWMM ’92 Proceedings of the International Workshop on Memory Management (Springer- Verlag).
Woodhouse, Donald “JFFS: The Journaling Flash File System”, Proceeding of the Ottawa Linux Symposium, RetHat Inc., 2001.
Yang, Tianming, Feng, Dan & Liu Jingning. FBBM: A New Backup Method with Data De-duplication Capability. Qingdao: Multimedia and Ubiquitous Engineering, 2008.
Youjip, Won et al. Efficient index lookup for De-duplication backup system: Modeling, Analysis and Simulation of Computers and Telecommunication Systems. Ningbo: IEEE, 2008.