Data aggregation in healthcare is a vital process that facilitates medical research and analysis, as it provides access to the latest evidence acquired in hospital settings. Collecting many different types of information into one consolidated data asset is crucial for both scientists and managers.
According to Longhurst, Harrington, and Shah (2014), healthcare data in the form of electronic health records (ERDs) can be used for retrospective studies, which can replace randomized controlled trials as a cheaper alternative for acquiring scientific data. Additionally, Ramachandra (2018) states that hospital databases (DBs) can facilitate the work of hospital managers to provide the personnel with all necessary equipment and provisions. The present paper proposes a DB designed to accumulate statistical data for future analysis in the sphere of clinical tests.
Synapsis
Problem Statement and Key Terms
The effectiveness of clinical tests (CTs) is a major concern for hospital managers and researchers in medicine. According to Manchanda et al. (2014), inefficient screening and testing procedures can be the reason for additional unsuspected spending. Additionally, Ramachandra (2018) points out that one of the most complex challenges for hospital managers to provide all the staff with appropriate authority and resources to perform their duties. A well-organized easy-to-use database dealing with testing procedures may lead to improvements in both spheres mentioned above.
The present paper uses the following key terms:
- Database (DB). A structured set of data stored in a server that is used for effective information organization and retrieval.
- Diagnosis. A condition that a patient may have according to the symptoms.
- Clinical Test (CT). A diagnostic procedure used to detect or monitor medical conditions.
Identifying the Users
The proposed database will be used by medical professionals, hospital managers, researchers, and a system administrator. The group of medical professionals includes doctors, nurses, and laboratory personnel. These users are competent in the medical aspect of the database, as they are mostly aware of the CTs’ names and their prescription guidelines. The second group includes the board of directors and supervisors, who are in charge of identifying the efficiency of medical procedures and creating evidence-based guidelines for the hospital staff.
The researchers are aware of both data organization and the medical aspect. Additionally, the DB will be supported by a system administrator with limited knowledge about the medical issue of the database. The DB proposed in the present paper is designed to meet the need of all the potential users.
The Information Needed
The introduced DB requires compiling a substantial amount of information. First, the DB will include information about all the CTs practiced by a hospital. This information may differ among the facilities and, therefore, needs to individual approach for data aggregation. Second, the proposed design requires entering information about all the doctors and patients of a hospital. This security-sensitive data needs to be entered by a DB administrator with special care. Finally, the DB involves gathering information about all the possible diagnoses, which is a labor-consuming effort. However, the medical conditions are universally accepted, therefore, this part can be pre-entered by the developers. The aggregation is needed to evaluate the efficiency of procedures and create evidence-based hospital policies.
Goals and Objectives
The primary goal of this project is to design a sample DB that will facilitate data mining in the field of CTs. The objectives of the system are:
- Aggregate all the relevant information described in the previous section;
- Organize all the data according to relations among the assets;
- Identify user roles and their rights.
According to Coronel and Morris (2019), as the database will need to describe correlations among therapeutic indications of different substances, the database will have an entity-relational database model.
Steps towards the Goal
Below are the steps suggested by Coronel and Morris (2019) to design an efficient database:
- Step 1. I will discover and describe the business rules of the hospital.
- Step 2. I will choose a data model according to the business process of a medical institution.
- Step 3. I will identify all the entities, attributes, relationships, and constraints of the model.
- Step 4. I will gather all the necessary information that needs to be entered into the database.
Potential Problems
The potential problems are connected to the specific characteristics of the DB and general concerns of implementations of new procedures. First, the DB requires a large amount of data regarding all the possible diagnoses and CTs that needs to be compiled. Second, there may appear a problem with training the personnel to use the newly-introduced DB, as it may seem overly resource-consuming. Third, the DB deals with security-sensitive data that needs to be adequately protected. In short, the list of potential problems includes objective and subjective factors.
Hosting Considerations
As the information stored in the proposed database will be in the text rather than multimedia, the server is required to be high-end. Despite the possible security implication, it would be beneficial to use cloud services for hosting, as it is a more cost-effective method of computing (Coronel & Morris, 2019). According to iWeb, the optimal characteristics for the server would be as follows (“Hardware Guide,” n.d.):
The proposed server can be rented and changed if it is underused or does not meet the hospital’s needs.
Required Resources and Estimated Budget
The required resources and estimated budget may differ considerably depending on the staff and equipment used by a hospital. As it was proposed to use cloud computing for data warehousing, the hospital will not need to spend additional money on new computers, or wiring (Coronel & Morris, 2019). The annual cost of DB maintenance will consist of a DB administrator salary of approximately $61,000 a year (“Average systems administrator salary,” n.d.), and payments for the hosting, $3,000 a year (“Hardware Guide,” n.d.).
However, the initial setup cost may be a matter of concern, as it is closely connected to the number of employees hired by the facility. Hospitals will have to pay two additional hours of training for every employee that will be using the database. In summary, the estimated budget needs to be counted specifically for every organization to avoid misleading.
Design Proposal
Entity Relation Diagram
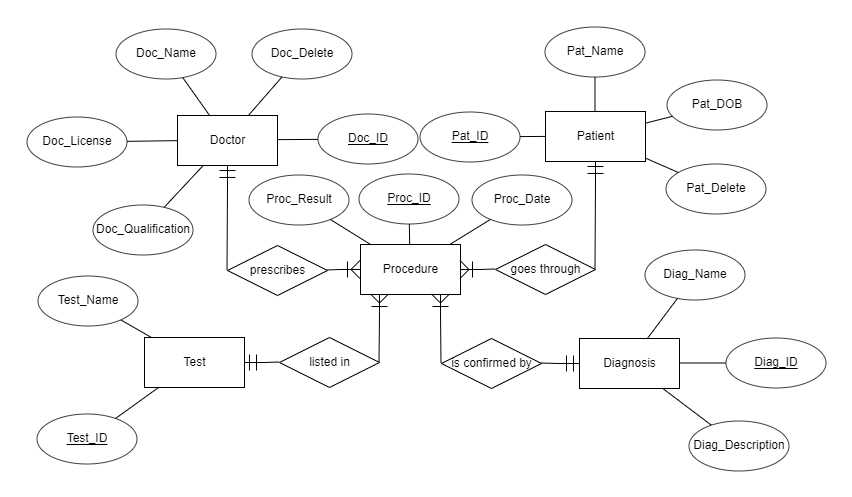
Relational Schema
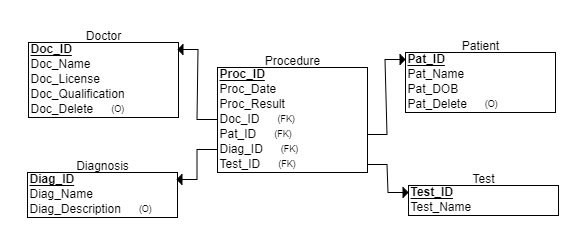
Data Dictionary
SQL Statements
— Student Name
— Course Number
— Date
— This is my own work.
.open TestDB
.header on
.mode column
CREATE TABLE Doctor
(
Doc_Name VARCHAR(50) NOT NULL,
Doc_License INT NOT NULL,
Doc_ID INT NOT NULL,
Doc_Delete DATE,
Doc_Qualification VARCHAR(24),
PRIMARY KEY (Doc_ID)
);
CREATE TABLE Patient
(
Pat_Name VARCHAR(50) NOT NULL,
Pat_ID INT NOT NULL,
Pat_DOB DATE NOT NULL,
Pat_Delete DATE,
PRIMARY KEY (Pat_ID)
);
CREATE TABLE Diagnosis
(
Diag_ID INT NOT NULL,
Diag_Name VARCHAR(50) NOT NULL,
Diag_Description VARCHAR(255),
PRIMARY KEY (Diag_ID)
);
CREATE TABLE Test
(
Test_Name INT NOT NULL,
Test_ID INT NOT NULL,
PRIMARY KEY (Test_ID)
);
CREATE TABLE Procedure
(
Proc_ID INT NOT NULL,
Proc_Date DATE NOT NULL,
Proc_Result VARCHAR(24),
Doc_ID INT NOT NULL,
Pat_ID INT NOT NULL,
Diag_ID INT NOT NULL,
Test_ID INT NOT NULL,
PRIMARY KEY (Proc_ID),
FOREIGN KEY (Doc_ID) REFERENCES Doctor(Doc_ID),
FOREIGN KEY (Pat_ID) REFERENCES Patient(Pat_ID),
FOREIGN KEY (Diag_ID) REFERENCES Diagnosis(Diag_ID),
FOREIGN KEY (Test_ID) REFERENCES Test(Test_ID)
);
Database Population
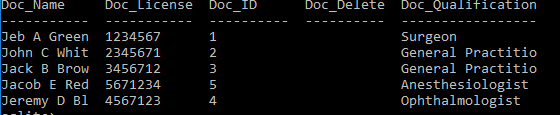
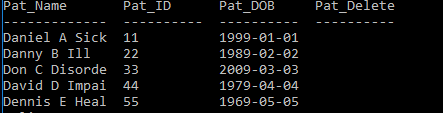
To acquire an appreciation of the DB design, it is beneficial to populate the proposed database with data. Based on the previous experience in DB design, it was chosen to provide five rows of data for every table, as it sufficient to demonstrate DB future use in the hospital settings. Below are the statements to add fictional data with screenshots of SELECT * FROM queries. The attributes for soft deletion are not populated, as they are marker columns that will be used when data is deleted from the DB.
.open TestDB
.header on
.mode column
INSERT INTO Doctor (Doc_ID, Doc_Name, Doc_License, Doc_Qualification) VALUES (‘1’, ‘Jeb A Green’, ‘1234567’, ‘Surgeon’) ;
INSERT INTO Doctor (Doc_ID, Doc_Name, Doc_License, Doc_Qualification) VALUES (‘2’, ‘John C White’, ‘2345671’, ‘General Practitioner’) ;
INSERT INTO Doctor (Doc_ID, Doc_Name, Doc_License, Doc_Qualification) VALUES (‘3’, ‘Jack B Brown’, ‘3456712’, ‘General Practitioner’) ;
INSERT INTO Doctor (Doc_ID, Doc_Name, Doc_License, Doc_Qualification) VALUES (‘4’, ‘Jeremy D Black’, ‘4567123’, ‘Ophthalmologist’) ;
INSERT INTO Doctor (Doc_ID, Doc_Name, Doc_License, Doc_Qualification) VALUES (‘5’, ‘Jacob E Red’, ‘5671234’, ‘Anesthesiologist’) ;
INSERT INTO Patient (Pat_ID, Pat_Name, Pat_DOB) VALUES (‘11’, ‘Daniel A Sick’, ‘1999-01-01’) ;
INSERT INTO Patient (Pat_ID, Pat_Name, Pat_DOB) VALUES (‘22’, ‘Danny B Ill’, ‘1989-02-02’ ) ;
INSERT INTO Patient (Pat_ID, Pat_Name, Pat_DOB) VALUES (‘33’, ‘Don C Disordered’, ‘2009-03-03’ ) ;
INSERT INTO Patient (Pat_ID, Pat_Name, Pat_DOB) VALUES (‘44’, ‘David D Impaired’, ‘1979-04-04’) ;
INSERT INTO Patient (Pat_ID, Pat_Name, Pat_DOB) VALUES (‘55’, ‘Dennis E Healthy’, ‘1969-05-05’) ;
INSERT INTO Diagnosis (Diag_ID, Diag_Name, Diag_Description) VALUES (‘111’, ‘Breast Cancer’, ‘Malignant tumor in breasts’) ;
INSERT INTO Diagnosis (Diag_ID, Diag_Name, Diag_Description) VALUES (‘222’, ‘Lung Cancer’, ‘Malignant tumor in lungs’) ;
INSERT INTO Diagnosis (Diag_ID, Diag_Name, Diag_Description) VALUES (‘333’, ‘Eye Cancer’, ‘Malignant tumor in eyes’) ;
INSERT INTO Diagnosis (Diag_ID, Diag_Name, Diag_Description) VALUES (‘444’, ‘Brain Cancer’, ‘Malignant tumor in brain’) ;
INSERT INTO Diagnosis (Diag_ID, Diag_Name, Diag_Description) VALUES (‘555’, ‘Liver Cancer’, ‘Malignant tumor in liver’) ;
INSERT INTO Test (Test_ID, Test_Name) VALUES (‘1111’, ‘Biopsy’) ;
INSERT INTO Test (Test_ID, Test_Name) VALUES (‘2222’, ‘Clinical Blood Analysis’) ;
INSERT INTO Test (Test_ID, Test_Name) VALUES (‘3333’, ‘Immunologic Blood Test’) ;
INSERT INTO Test (Test_ID, Test_Name) VALUES (‘4444’, ‘Clinical Urine Analysis’) ;
INSERT INTO Test (Test_ID, Test_Name) VALUES (‘5555’, ‘Feces Analysis’) ;
INSERT INTO Procedure (Proc_ID, Proc_Date, Proc_Result, Doc_ID, Pat_ID, Diag_ID, Test_ID) VALUES (‘11111’, ‘2019-02-03’, ‘Positive’, ‘1’, ‘11’, ‘222’, ‘1111’) ;
INSERT INTO Procedure (Proc_ID, Proc_Date, Proc_Result, Doc_ID, Pat_ID, Diag_ID, Test_ID) VALUES (‘22222’, ‘2019-02-03’, ‘Not Clear’, ‘2’, ‘55’, ‘444’, ‘4444’) ;
INSERT INTO Procedure (Proc_ID, Proc_Date, Proc_Result, Doc_ID, Pat_ID, Diag_ID, Test_ID) VALUES (‘33333’, ‘2019-02-04’, ‘Not Clear’, ‘2’, ‘55’, ‘444’, ‘5555’) ;
INSERT INTO Procedure (Proc_ID, Proc_Date, Proc_Result, Doc_ID, Pat_ID, Diag_ID, Test_ID) VALUES (‘44444’, ‘2019-02-05’, ‘Negative’, ‘2’, ‘55’, ‘444’, ‘1111’) ;
INSERT INTO Procedure (Proc_ID, Proc_Date, Proc_Result, Doc_ID, Pat_ID, Diag_ID, Test_ID) VALUES (‘55555’, ‘2019-01-29’, ‘Positive’, ‘2’, ‘33’, ‘333’, ‘1111’) ;

Proposed SQL Reports
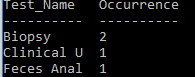
The proposed database design is useful for acquiring statistical data on numerous matters including the efficiency of tests to confirm a diagnosis and monthly demand for a procedure in the proposed timeframe. Below is the query to create a report about the demand for biopsy in February 2019. It is an example of a monthly report that can help a hospital manager to estimate the future utilization of a certain procedure and take appropriate measures to ensure the availability of needed provisions and specialists.
.open TestDB
.header on
.mode column
SELECT Test_Name,
COUNT(Procedure.Test_ID) AS ‘Occurrence’
FROM Test, Procedure
WHERE Test.Test_ID=Procedure.Test_ID
AND Proc_Date >=’2019-02-01’
GROUP BY Procedure.Test_ID;
The proposed database, as it was mentioned earlier in the present paper, can be used for medical studies to identify the cost-effectiveness of a procedure. Researchers can utilize the DB to acquire statistics about how often the results of a test were not clear for a certain diagnosis. The information can be used to elaborate evidence-based guidelines for hospital staff to prescribe the procedure to confirm different diagnoses. Below is the query to create a report that would be useful for the researchers.
.open TestDB
.header on
.mode column
SELECT Test_Name, Diag_Name,
COUNT(Proc_Result) AS ‘Not Clear Occurrence’
FROM Test, Diagnosis, Procedure
WHERE Proc_Result=’Not Clear’
AND Procedure.Test_ID=Test.Test_ID
AND Diagnosis.Diag_ID=Procedure.Diag_ID
GROUP BY Test_Name;

Design Difficulties
While designing the database I encountered two significant difficulties that appeared troublesome to overcome. First, it was challenging to describe all the relations among entities through a diagram, as it was unclear whether the Doctor entity should correlate to the Patient table directly or indirectly. However, a more in-depth analysis leads to understanding that the addition of Doctor attribute to the Patient entity was inappropriate, as a patient may be associated with many doctors.
Second, it was problematic to decide whether the DB should use soft or hard deletion. Even though soft data removal can lead to problems with storage and privacy issues, it was decided to use the method, as it prevents possible human errors and preserves the data for retrospective analysis (Ben-Assuli, 2015). Therefore, the DB design includes marker columns for soft deletion in Patient and Doctor tables.
User Roles
The rationale for user rights and restrictions is connected to the potential users previously discussed in the present paper. The DB is projected to be used by medical professionals, hospital managers, researchers, and a system administrator. The medical professionals will be divided into two groups: doctors and laboratory workers. Doctors will assign Procedures to Patients, and, therefore, will be granted with rights to add and modify information about associated procedures.
However, these users will not be able to edit or add any data about patients, possible diagnoses, and CTs. Laboratory workers are supposed to fill in information about test results with no additional rights. Hospital managers and researchers will be treated as observers and will have the right to compile reports without the ability to create, modify, or delete rows of data. Finally, the administrator role will be associated with access to all the functions of the database. In summary, the DB is designed to be used by four user groups: doctors, laboratory staff, observers, and an administrator.
Design Rationale, Limitations, and Extensions
The design was developed to meet all the needs of people working with CTs on hospital grounds. All the decisions were made under database design demands offered by Coronel and Morris (2019), which include design elegance, processing speed, and information requirements. The proposed model includes a massive amount of information that can be easily accessed after a training course. In short, the design was chosen for its simplicity and efficiency.
The limitations of the design are closely connected with the possible future extensions. First, the DB does not include all the possible test results creating a strong possibility of human error in the results entering. Therefore, one of the possible extensions will be to add the Results table that will include all the possible variants of CT results. The addition will decrease the likelihood of data integrity issues allowing effective data mining and reporting.
Second, the DB is limited to deal strictly with CTs and does not offer any information about drugs and prescriptions. The proposed design is similar to the traditional DBs that deal with pharmaceutical products, therefore, it would be consequential to extend the current project to include measures for drug management on hospital grounds. In brief, even though the design is chosen for its efficiency and information requirements, it can be improved or become a part of a larger hospital database.
Conclusion
The efficiency of CTs is a concern that requires additional research in the matter. One of the methods to facilitate studies in the sphere is retrospective research that can benefit from hospital DBs. Even though the design proposed in the present paper corresponds to all the requirements of an effective DB suggested by recent studies, it must be treated as a template that can be modified to meet the needs of any facility.
References
Average systems administrator salary. (n.d.). Web.
Ben-Assuli, O. (2015). Electronic health records, adoption, quality of care, legal and privacy issues and their implementation in emergency departments. Health Policy, 119(3), 287-297. Web.
Coronel, C., & Morris, S. (2019). Database systems: Design, implementation, and management (13th ed.). Web.
Hardware guide. (n.d.). Web.
Longhurst, C., Harrington, R., & Shah, N. (2014). A ‘green button’ for using aggregate patient data at the point of care. Health Affairs, 33(7), 1229-1235. Web.
Manchanda, R., Legood, R., Burnell, M., McGuire, A., Raikou, M., Loggenberg, K., … Jacobs, I. (2014). Cost-effectiveness of population screening for BRCA mutations in Ashkenazi Jewish women compared with family history–based testing. JNCI: Journal of the National Cancer Institute, 107(1). Web.
Ramachandra, D. (2018). Essentials of Hospital Management & Administration. New Delhi, India: Education Publishing.