Introduction
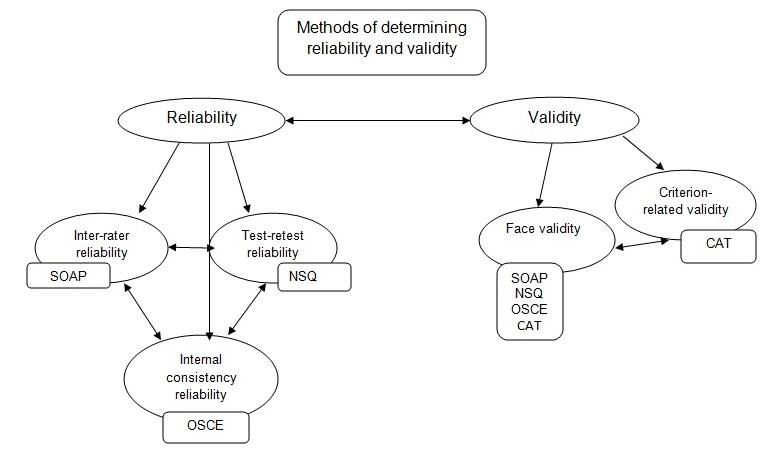
Reliability and validity are significant elements of any assessment tool. However thoroughly developed the tools are, if they are not valid or reliable, the research is doomed to fail. Reliability is the rate of consistency which involves the following methods: inter-rater, parallel forms, test-retest, and internal consistency. Validity is the extent to which an assessment tool is accurate and corresponds to the real world. Validity evaluation methods are: face, criterion-related, sampling, formative, and construct efficacy.
Inter-Rater Reliability
Inter-rater reliability is concerned with the stability of assessment tools when employed by different participants. This method is rather complicated since every person has a peculiar opinion on different things. When the assessment tool inquires for the participants’ opinions, its reliability is quite poor since the tool is subjective. However, if an assessment tool inquires for people’s answers about definite facts, reliability is enhanced as the tool becomes subjective. While the inter-rater method may be subjective, it is valuable since it presents an opportunity to compare diverse responses (Barrett, Wilson, & Woollands, 2012).
The method can be employed to check the Structured Observation and Assessment of Practice (SOAP).
Test-Retest Reliability
This method presupposes the participants to answer the same questions two times in order to provide greater reliability. The method is successful if the correlation rates are high.
The disadvantages of this method include the necessity to obtain the participants’ agreement to take the same test twice and the difficulty in discriminating between the actual change and the deficiency of a trustworthy measure. In the time range between the two tests is too long, there may be a substantial change between the answers, and the equivalence will be low (Acock, 2008).
This method can be used to assess the Nursing Competencies Questionnaire (NCQ).
Internal Consistency Reliability
This is the most prevalent reliability measure for assessment tools. It is favored due to the simplicity of the application. This method demands one data sample which enables the estimation of the internal consistency reliability (Sauro, 2015). The approach evaluates the regularity with which the participants answer to one set of components. The method, which is often called Cronbach’s alpha, fluctuates from 0.0 to 1.0 (Sauro, 2015). The minimal allowed range of reliability is 0.70. However, especially important tests target for no less than 0.90 (Sauro, 2015). The more items there are in the questionnaire, the higher reliability it has. If the number of items cannot be high, reliability can be gained through the extension of the sample size (Acock, 2008).
This method can be employed to assess the Objective Structured Clinical Examination (OSCE).
Face Validity
This method determines that the tool is assessing the predetermined construct. The stakeholders can easily estimate whether the test has face validity (Polit & Beck, 2008). If they consider that the test lacks it, they will not be interested in participating. While this type of validity is not very scientific, it is rather significant (Shrock & Coscarelli, 2007).
Face validity should be used for each of the assessment tools.
Criterion-Related Validity
Criterion-related validity is applied for a prediction about the current or future outcomes (DeVellis, 2012). As well as face validity, this method is rather practical than scientific, but it is essential for the research. The approach is often called predictive validity as it does not involve comprehending the process but simply implies foreseeing it. The most essential feature of this method is the intensity of the empirical connection between the measure and the criterion (DeVellis, 2012).
The method can be applied to evaluate the Competency Assessment Tool (CAT).
Conclusion
There is a diversity of methods of determining the validity and reliability of assessment tools. While reliability is significant, it is not enough to consider the tool valid. Usually, one approach is enough to prove your tools as reliable and valid. However, to establish the most precise evaluation, a combination of several methods may be employed.
Appendix
Concept map
References
Acock, A. C. (2008). A gentle introduction to stata (2nd ed.). Texas, TX: Stata Press Publication.
Barrett, D., Wilson, B., & Woollands, A. (2012). Care planning: A guide for nurses (2nd ed). New York, NY: Routledge.
DeVellis, R. F. (2012). Scale development: Theory and application (3rd ed.). Thousand Oaks, CA: SAGE.
Polit, D. F., & Beck, C. T. (2008). Nursing research: Generating and assessing evidence for nursing practice (8th ed.). Philadelphia, PA: Wolters Kluwer/ Lippincott Williams & Wilkins.
Sauro, J. (2015). How to measure the reliability of your methods and metrics. Measuring Usability. Web.
Shrock, S. A., & Coscarelli, W. C. (2007). Criterion-referenced test development: Technical and legal guidelines for corporate training (3rd ed.). San Fransisco, CA: Pfeiffer.