The research question for the study under analysis can be put in the following way: what are the key differences between the delivery methods on the students’ statistical skills acquisition between various courses? The statistical notation for the null hypothesis in the study (the supposition that the face-to-face delivery will result in a considerably higher score than the remaining two groups) can be expressed with the help of the corresponding formula. For example, supposing that the online delivery score is xn, the face-to-face delivery score is yn, and the hybrid one is zn. Therefore, according to the null hypothesis, the former and the latter will not exceed the x2 score. Seeing that the number of students has not been defined, the statistical notation for the null hypothesis will look the following way:
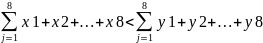
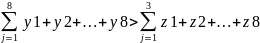
The alternative hypothesis, which says that other differences are possible, presupposes that two more notations should be created; for example, it may happen that the students have the same scores in each of the activities; in this case, the statistical notation will have a following look:
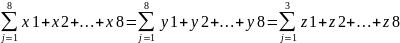
It can also be assumed that the scores for the online tests will be higher than in the rest of the two groups; in this case, the statistical description will be expressed as
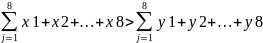
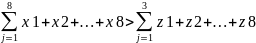
Finally, it can be assumed that the hybrid test will result in students getting the highest mark possible, whereas, in the rest of the tests, the grades will be lower; therefore, the following distribution can be considered as an option:
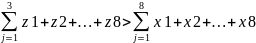
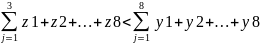
In the example specified, the types of tests can be identified as dependent (continuous, categorical, nominal) variables, whereas the performance of the students (the test scores) is the independent (discrete, quantitative, ordinal) variables (Kraiger & Kirkpatrick, 2010).
The descriptive statistics for the experiment in question should embrace the quality of performance among the students and the scores that students had on average in each type of the test in question. Thus, it will be possible to compare the efficacy of each test. It should be kept in mind, though, that a range of other, both internal and external, factors affect students’ test scores; therefore, when considering the descriptive statistics for the college students and the efficacy of the tests under analysis, one must take the statistical data with a grain of salt.
It should be kept in mind that eight students took part in the study. The number of points possible is 100, each question being worth one point; therefore, there are 100 questions to answer total. The measures of central tendency, particularly the arithmetic mean, allow for analyzing the degree to which the analysis in question can be accurate. Because of a relatively small amount of participants and, therefore, a comparatively small scale of the research, the results can be viewed as rather subjective; hence, the need to evaluate the credibility of the test results emerges and the data in question allow for it (Coughlan, Cronan & Ryan, 2007).
The same can be said about the distribution of the ratio variables – the average mean helps identify the extent to which the data obtained from taking one of the tests specified differs from the statistical data acquired from the results of the students taking other tests. It is crucial that the introduction of central tendency allows for adding such an important parameter as mean to the measurement tools, therefore, allowing for the transfer from the stage of the ordinal level of measurement to the interval/ratio measurement stage.
Indeed, with the inclusion of mean into the list of variables, the rate of specific data can be calculated; as a result, the possibility to switch to the statistical representation of data emerges. As far as the nominal and ordinal variables are concerned, it will be impossible to carry out the descriptive statistics analysis, since they do not presuppose that the mean should be calculated (Ray & Webster, 2010).
In the course of the research, it was chosen to conduct the Statistics Skills Test. The choice of such a type of ANOVA test is quite obvious; it allows for determining the variables required for the hypothesis to be proven. To be more exact, the test helps identify and measure the variables based on their mean. It is crucial that the chosen type of tests is multivariable; in other words, it allows for incorporating two and more variables into the research.
Since the study in question includes several factors that shape the students’ performance in college, the introduction of a multivariable quality to the test used in the study is an important step towards proving the research hypothesis successfully. More importantly, the specified type of ANOVA tests helps identify and analyze the relationships between the variables under analysis; therefore, the test can be characterized as a factorial one. Indeed, unlike a one-way ANOVA test, the factorial assessment includes every single factor into consideration, therefore, contributing to a more accurate analysis and more precise results received (UIS, n.d.).
In the course of the research, a posthoc test was conducted as well, which was an integral part of proving the research hypothesis (Huck, 2012). Because of the specifics of the test, it could be expected that other research results besides the null hypothesis and the alternative hypothesis could emerge. In other words, some of the test outcomes could not have been defined a priori and, therefore, might come into the limelight only after the test was carried out. As a result, the post-hoc analysis had to be made.
Apart from the relationships between the key variables, the post-hoc test could reveal other factors that may have affected the research participants and changed the outcomes of the test. In addition, it is important to keep in mind that a test based on the data acquired from average means of the factors may lack precision; consequently, it is necessary to conduct a posthoc test in order to make sure that the test has provided credible data. Thus, two post-hoc tests were taken; the first one was supposed to address the possible errors in the mean square (40.774 (Week 3 – SPSS output, 2014)), whereas the second one addressed the means for groups in homogeneous subsets.
The research results say that the hypothesis has been confirmed since the face test participants have shown the highest marginal means on the statistic skills test. The results, therefore, show that ANOVA tests provide credible results when it comes to analyzing experimental data in order to address the effects of a limited amount of factors. The test, however, cannot be used with a single source of variation. Finally, the study has proven that the data must be collected with regard to the homogenous students (Week 3 – SPSS output, 2014).
Reference List
Coughlan, M., Cronan, P., & Ryan, F. (2007). Step-by-step guide to critiquing research. Part 1: quantitative research. British Journal of Nursing, 16(11), 658-663. Web.
Huck, S. W. (2012). Reading statistics and research (6th ed.). Boston, MA: Pearson.
Kraiger, K., & Kirkpatrick, S. (2010). An empirical evaluation of three popular training programs to improve interpersonal skills. Journal of Psychological Issues in Organizational Culture, 1(1), 60-73. Web.
Ray, R. D., & Webster, R. (2010). Group interpersonal psychotherapy for veterans with posttraumatic stress disorder: A pilot study. International Journal of Group Psychotherapy, 60(1), 131-140. ProQuest. Web.
UIS. (n.d.). How to critique a journal article. Web.
Week 3 – SPSS output. (2014) PDF file. Retrieved from the University of Rockies database.