Introduction
To describe language as a social reality, urban sociolinguistic studies seek to establish connections between language and society. This survey concentrated on one well-known phonological feature: (t, d) deletion, which has been widely studied in the UK (Tagliamonte & Temple, 2005). This work uses quantitative methodologies to investigate patterns of (t, d) deletion variation across genders to avoid making inferences based just on individual facts. (t, d) deletion is this research’s dependent variables that are being studied in this research. For the independent variable, the sociolinguistic component group selected is gender. The proposed research question is, are deletion rates for word-final /t, d/higher among women than among men? The hypothesis is that gender predicts (t, d)-deletion, as deletion rates for word-final (t, d) were higher among women than among men. However, findings in this study suggest that gender does not predict deletion. This paper consists of background and hypotheses, data and methods used, results, and discussion.
Background and hypotheses
The dependent variable addressed in this study is (t, d) deletion, which is the alternation between [t, d] and [e, d]. A phonological variable, by virtue of being part of morphology, might be designated as a dependent variable (Baranowski & Turton, 2020). The binary logistic regression analysis of deletion vs. [t, d] was employed in this research (Wardhaugh & Fuller, 2015). The study looked into components that suggest the [t, d] deletion frequencies across gender. Small discrepancies between phonological and phonological factors, as well as universal phonological and phonetic characteristics of segments like phonological setup, are included in these parameters (Tagliamonte & Temple, 2005). Statistical analysis includes the idea of language usage in addition to significance tests when looking at linguistic variables as an output of a system (Baranowski & Turton, 2020).
The sociolinguistic component of gender was selected as the independent variable. Perspectives from both male and female English speakers on [t, d] deletion frequencies were significant for this research (Wardhaugh & Fuller, 2015). According to this study, gender-based deletion (t, d) should be examined in order to clear up any ambiguity. This study focused on the gender of the speakers because previous research had not been able to provide enough information to draw any firm conclusions. The gender of the subject was denoted using a binary variable (male or female). According to the proposed hypotheses, (t, d)-deletion is affected by gender and that women have higher deletion frequencies for word-final (t, d) than males. Consequently, an important part of this hypothesis is determining whether or not there are any gender differences in the dataset.
Data and Method
A quantitative research method was used in this research. A binary categorization of the word that contained the token was used in the current study to separate out unique aspects of the word form (missed, tend) (Wardhaugh & Fuller, 2015). The study concentrated on two words: “missed” and “tend.” For the two words, the overall frequencies were calculated on the basis of percentages, with each participant identifying how words would sound the same after (t, d)-deletion.
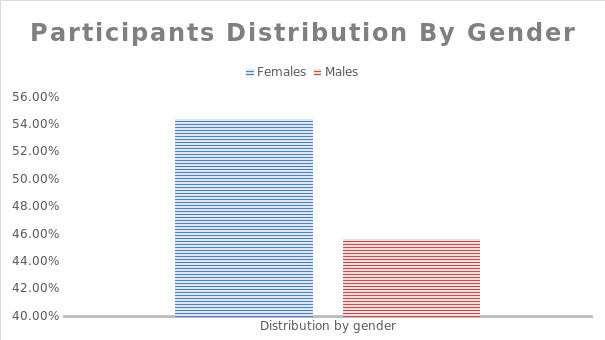
The questions for the dependent variable (t, d)-deletion dataset included: does “miss” sound the same as “missed,” and does “tent” sound the same as “ten”? Data was collected from Northern Ireland, Wales, the Republic of Ireland, and parts of England. Participants came from the East of England, North and Yorkshire and Humber. They also came from East Midlands. The West Midlands and the South East also had people. Of the total respondents (n =843), 54.4% (n =459) were female, while 45.6% (n =384) were male. Therefore, more women than men took part in the research.
Table 1. Participant distribution by gender
Results
Frequency of use
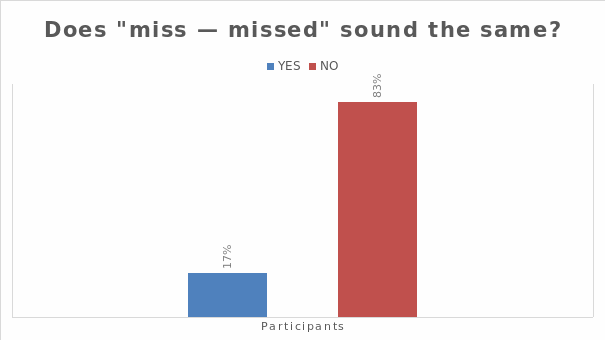
Of the 843 participants, (17%) stated that “Miss and Missed” would pronounce the same (non-standard), while 83% stated they would pronounce differently (standard pronunciation).
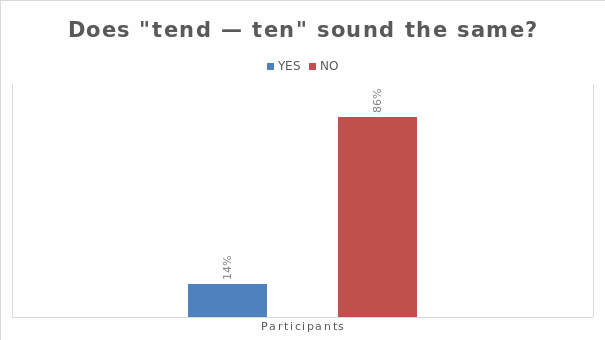
Additionally, 14% stated that “tend” and “tend” would pronounce the same, while 86% stated they would pronounce differently.
From this result, standard pronunciation is favoured among the participants.
Linguistic predictor
The main difference between how “t” and “d” are pronounced in the words “tend” and “missed” can also be analyzed by looking at the linguistic predictor, such as the morphological class. There is a higher rate of deletion in the word “missed” (17%) than in “tend” (14%).
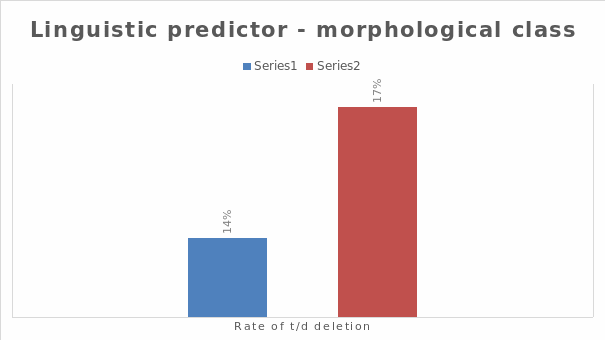
This shows that monomorphemic words like “tend” are deleted at lower rates than regular past tense forms like “missed.” This contradicts an earlier study of British English that found deletions to be higher in monomorphemic words than in regular past tense forms (Baranowski & Turton, 2020).
Social predictions (gender)
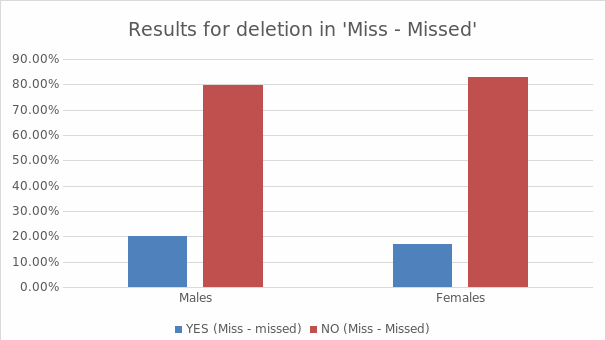
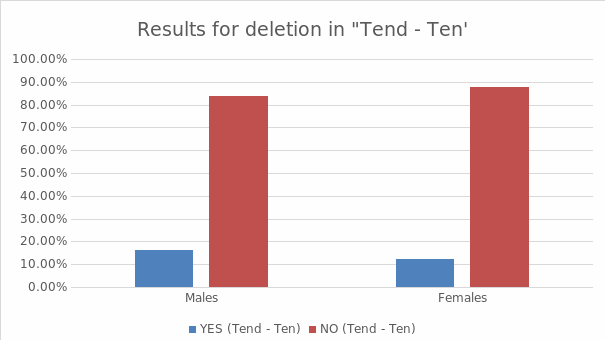
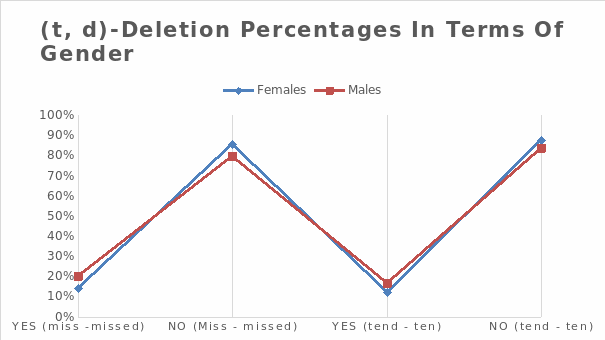
Findings suggest that 20.1% (for misses—missed) is more for men than women (14.4%). This also happened in “tend-ten,” where men exhibited higher deletion rates (16.4%) than women (12.4%) (see figure 3).
However, the difference is insignificant as more men and women reported that there was no deletion in words that contained the token. Only 17% of both men and women exhibited deletion in “miss—missed,” while a majority (83%) did not. Only 14.2% of these people had deletions in ‘tend-ten’, while the majority (85%) didn’t (see table 3). This contrasts with earlier findings by Guy (1992), which showed that deletion rates for word-final/t, d/were higher among women than among men.
This disproves the hypothesis that gender predicts (t, d)-deletion, as deletion rates for word-final (t, d) were higher among women than among men. Therefore, the absolute and relative rate measures given above do not provide an explanation for gender in the parameters influencing deletion.
Table 3. (t, d)-deletion
Discussion
As established in this research, T/D retention may be more likely to occur than deletion when measuring gender as a sociolinguistic predictor. The dataset showed that gender does not predict deletion. This was a consistent part of the modeling process as it showed up in all token subsets, indicating that gender may not necessarily be involved or explain the observed influence on deletion (Pavlk, 2017). Since the respondent’s pronunciations were not measured, as only their views on (t, d)-deletion in the two content words were studied, there is an underling weakness in this research. Additional research is, therefore, needed to shed more insight on this discrepancy, which is most likely due to different speaking styles (formal vs. casual) or the pace of speech between women and men.
Conclusion
This study used quantitative approaches to explore patterns of (t and d) deletion variance across gender. Gender was chosen as the sociolinguistic component group for the independent variable. Is the deletion rate for word-final/t, d/deletion higher in women than in males, according to the proposed study question? Gender was hypothesised to predict (t, d)-deletion. However, it is found that gender does not appear to be a factor in deletion. This was a constant aspect of the modeling process since it appeared in all token subsets, suggesting that gender may not be involved or explain the observed deletion impact.
References
Baranowski, M. & Turton, D. (2020). TD-deletion in British English: New evidence for the long-lost morphological effect. Language Variation and Change, 32, 1–23.
Pavlík, R. (2017). Some new ways of modeling t/d deletion in English. Journal of English Linguistics, 45(3) 195–228.
Tagliamonte, S., & Temple, R. (2005). New perspectives on an ol’ variable: (t,d) in British English. Language Variation and Change, 17, 281–302.
Wardhaugh, R., & Fuller, J. (2015). An introduction to sociolinguistics. John Wiley & Sons.