The process of sieving and preparing data can be time consuming. Some of the procedures are, normalization, cleaning, transformation and selection.
Missing values
Data may have missing values primarily for two main reasons. The first one is that the values could miss randomly or caused by unintentional error, for example interrupted data transmission by power failure. The second possible cause for missing values may be intentional or purposeful. For instance, a researcher fails to record an entry.
One-way to prevent missing value in data collection is to develop systematic methods of recording entries. Questionnaires should be formulated to prevent the possibility of missing an entry where one cannot input a value before the presiding one. In survey research, effective methods of data analysis are essential in avoiding the missing value.
There are applied techniques that detect the missing values. When the values are missing at random, the probability theory P(X,Y) can be applied to revive the process of P(X). In addition, expectation-maximization (EM) algorithm may be used to assimilate missing values.
There are strategies of dealing with missing value in data mining process. Ignoring the sequence: This method is applied if the labeling is missing. Here the mining work involves classification. This method usually does not work effectively unless the sequence has numerous attributes with their values missing. This method can be detrimental if the percentages of the missing value per attribute considerably vary.
The missing value can also be filled manually although this approach is time consuming and not realistic in large-scale database with missing values.
One may apply a universal constant as the missing value. This is done by replacing all attributes that are missing with common constant. This is a simple method but not fool proof. Similarly, one can apply the attributes mean as the missing value.
Outliers
Outlier in statistics is a numerically different from data collected. Outlier can have many causes. Some of the possible causes could be human or machine error. Error could occur in data transcription or malfunctioning of measuring apparatus. Alternatively, a flaw in applied theory could be a cause of outlier. An outlier cannot be defined mathematically and its determination by an observer is subjective.
There applied techniques and systems used in detection of outlier. The main approaches to detection are,
- Determining the outlier without information of the data this similar to clustering that is not supervised. This approach lays the data as static distribution indicates the furthest points and shows them as outliers.
- The second model applied in detection is the normality and abnormality models. This approach is similar to supervised classification and only works with pre-labeled data.
- The other model used is the normality or the abnormality that is seldom used. This approach is almost similar to quasi- supervised task.
How to deal with outlier is dependent on the cause.
In retention, during the application of the normal model in data analysis, outliers should not be dismissed in bigger sample sizes. This process need to employ a classification logarithm vigorous to outlier, to model data that has naturally occurring points.
Many scientists do not welcome deletion of outlier and find it controversial. The mathematical procedure offers a quantitative and an objective process for rejection of data. This however, does not make the procedure scientifically coherent; more so in case a normal distribution is not deduced. Rejection is allowed in cases where the critical model of the measured process and the normal measurement distribution error are positively identified.
An outlier that is caused by reading error of an instrument can be rejected but it is also a good practice to verify the reading first.
In the case of non-normal distributions, one would likely contemplate that the critical distribution of the data is mot generally normal. For example, when a sampling from a continuous probability distribution, sample variance is directly proportionate to the sample size and outliers are expected at bigger rates with the increase of sample variance.
Data mining
Figure i example data base with 4 items and % transactions.
- Lift is a measure of the effectiveness of a model at classifying samples appraising it against an unexpected choice model.
For example;
The rule {Soda, milk} = {Bread} has a lift of
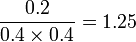
- Support is the degree of activity in the data set, which holds the item set.
For example,
Item set {soda, milk, bread} has a support of 1 / 5 = 0.2 because it appears in 20% of all activities in figure i (one in five transactions).
- Confidence can be explained as an estimate of the probability P(Y | X)
For example,
The rule {Soda, milk} = {Bread} shows a confidence of 0.2 / 0.4 = 0.5 in the sample database (figure i), this shows that for 50% of the transactions containing soda and milk the rule is correct.
Partitioning a dataset
Partitioning a dataset is a process done within a system of a computer. This process recovers product and transact data from the data bank. Here items are identified and arranged by attributes a user is interested in. calculation of the full length of the distribution curve is done and the curve divided into a number of partitions of equal pieces. The partitioned number remains constant and data selected is partitioned into classes that are consistent to the divisions of the curve.
The data can be subdivided into training, validation and test datasets. Training dataset is a set of samples used in study that is to fit the classifiers qualities. Validation data set is a set of samples used to refine the qualities of a classifier. Test set is a set of samples used to check the effectiveness of a fully specified classifier.
In evaluating data mining models, dividing data into training and testing set is essential. Usually, when a data set is partitioned into these two sets, most of the data is applied in training and a lesser portion is applied in testing. There should be similarity in the partitions to minimize the effect of inconsistency. Randomly analyzing data samples and is essential in understanding the qualities of the model.
The model is tested by measuring it against the test set. This is because the data testing set contain values for the attribute to be predicted.