Introduction
Today telecom industry is having ferocious competition where telecom service providers are trying to satisfy the customers. Despite various methods to attract and retain customers, customer churn remains a major challenge. In a more simplistic term, churn rate is the percentage of total customers who no longer use the telecommunication service of a particular operator after sometime as they turn towards rivals’ services. Thus, having a high churn rate can adversely affect the business.
Usually the customers churn due to several reasons; firstly, customers sign up for a product which don’t fully meet their requirements and/or they themselves don’t know what they want, thus they land up finishing with competitors. These customers don’t usually form a fidelity with the company. At the slightest issue, they tend to react negatively. On the other hand, if customers are explained and made conversant with requirements, they tend to stay happy with the products and services at their disposal.
Secondly, buying a product/service implies that some customers are looking for specific outcome. In case the key features don’t seem to work right, clients tend to get frustrated. So, the best way to counter this is to make sure that the company helps the clients in achieving their goals. Thirdly, frustrated clients don’t want to wait or chat with bots; neither do they want to wait for long before they can talk to someone who can help to solve their problem. Putting customer first is key to differentiate a brand and retain customers. A good customer service will enable to help those clients.
Whenever, product/services are not unique, leaving for competitor’s product becomes so easy that customers tend to believe that the other product(s) meet(s) the needs much better. To counter this, unique products or services tend to attract clients to that particular service. Besides, product reliability is of primordial importance. In case of slightest doubt, the clients tend to lose confidence in the product/service. To avoid this, we need to make sure that the service/product is bug free with minimal downtimes. The trust can be reinforced by clear communication towards the clients regarding any issue and also clarify their doubts if any.
Another churning reason is that clients tend to be fed up with a particular service/product. Customers do feel the need to innovate and cater for their future requirements. This can be done by tracking customer satisfaction over time. Building such rapport will have a much closer understanding and capture room for improvements. Likewise, pricing of any service/product needs to be balanced, where customers need to see value in what they are being proposed. Proper balancing in the willingness to pay and the value of the service is important.
Digging the churn predictors, we can try actions to retain those potential users. One way to do this is to recommend personalized product/services to clients using an AI based recommendation system. It can allow proposing customized solutions to customers. Furthermore, the AI system can be enhanced by a 360 feedback to track the performance and efficacy of the recommendations to learn how to make better and more precious prediction analysis.
Predicting churn with an AI recommender system will undoubtedly provide personalized user product so that retention probability is considerably increased. The recommender system examines the client-product relationship along with the conditions of the client. The primary goal of building such a system is to simplify the clients’ search of products or content. It restricts the variety of choices, so people can focus only on those products which they are really interested in.
Problem Statement /Research Problem
In telecom industry, to acquire new customers it comes with high cost. In order to decrease this cost, working towards retention of existing customers is important. Customers leave the network due to several reasons and they give an indication beforehand if they want to voluntarily or involuntary leave. Analyzing the existing data will help in predicting potential churners and actions can be taken accordingly in an attempt to retain these potential clients.
Whilst it is good to have prediction, the loop remains open as there should be actionable items so that the potential churners are retained in the telecom network. So following the churn prediction, the actions will be derived from an AI recommender system which will work in a hybrid model i.e using both collaborative and content-based filtering recommendation. This allows for predicting a better recommendation which can help in winning back the customers.
Today, even if the company is trying to manually do some kind of prediction over churn, they don’t have any digital platform which can regroup and provide recommendation of the actionable items. Everything today is being done with large percentage of error rate. Even defining some kind of business rules, churn prediction didn’t function as expected due to large data volume processing.
Voluntary churners are those who consciously stop using a particular service or product. Involuntary churners are also known as passive churners who leave the service or product due to some unavoidable reason such as insufficient funds, server errors etc.
So, the problem statement can be summarized as to reduction of cost for the company to acquire new clients, and provide recommendation for retention of the potential churners. This in turn will definitely reduce the OPEX of the company in the long run and increase profits.
Rationale of the Study
Predictive analysis of potential churners will help the company to decrease cost and increase customer satisfaction. It can vary from analyzing the number of calls to call centers, call drops, cell site overloads, customer trends in using the network etc. If we can predict what the customers are dissatisfied about, appropriate actions can be taken by specific departments in the company.
There are several tools already available in the industry for this. But due to data sensitivity, cost etc., the company doesn’t want to use any third party tool. Thus, my company is trying to build its own predictive AI model using its data lake available. Moreover, there are different algorithms to create churn. This thesis proposes at least 5 mechanisms which can be used for prediction in order to bring the most precise version of churners.
The prediction output will be at least two output columns; the first will be a binary value which will highlight whether the customer is a churner or not. The second column will highlight the probability which will determine the possibility of the customer to be a churner.
The study will also have an AI recommender system which will generate recommended actions for each potential churner. This will be based on previous peer-to-peer data and the users’ previous usage history. In this way, the recommendation will target the return on the network for the mobile user. Prior to providing recommendation, the system can create clusters of the potential churners which will regroup them based on certain criteria.
For the purpose of this thesis, the scope will be limited to the prepaid customers only.
Research Questions
For the study of this proposal, there are different research questions which will be addressed.
RQ1: What are the different AI techniques which can be used to predict prepaid telecommunication churners using deep learning?
Different techniques will be explored to identify which combination(s) can yield better results in this prediction. The implementation and comparison of different algorithm (at least five in my case) will enable the comparison so that we can know which one better analyses the data for churn prediction. For example (Alamsyah and Salma, 2018) predicted that employee churn varies based on the different evaluation model. The researchers found that the three popular algorithm Naïve Bayes, decision tree and random forest have yielded different accuracy level. However, it can be that deep learning will be more of use in order to unearth unseen tendencies and trend.
RQ2: Can different AI recommender system techniques be used to retain, potentially churning, telecom customers by providing solution(s)?
Based on the first request question, the output will be used in the second part of the thesis. So, once the potential churners have been identified and to produce actionable items, an AI Based recommendation system can be used. First and foremost, the potential churners can be clustered based on different like network-related churners, service-related churners, social-impact churners etc. Once this is done, the AI recommender system can make use of any kind of technique in the recommender system (collaborative, content-based, hybrid) to recommend the retention of the customers. For example, with peer-to-peer data and the users’ previous usage trend analysis, an AI recommender system can be optimal in providing a solution to win back the mobile user. He/she will only feel valued by the organization to be provided with such kind of approach. Today customers are at the center of each business and solution(s) is the key for their satisfaction.
The different recommendation techniques are:
- Collaborative filtering: recommendations based on similar preferences defined by different users in the past.
- Content-based filtering: recommendations based on previously bought items/services by the user. It can be based on name, location, preference etc. of the user previously.
- Hybrid filtering: a combination of both types of filtering defined previously.
Aims
How can prediction of potential churners help in retention of customers in telecom industry? The primary aim of the project is to have a cost reduction in the OPEX of the company while targeting an improved customer experience throughout the lifecycle of the customer. In this world of fierce battle of mobile operators, it is vital to not only meet the expectation but also exceed their needs. This, in term, only increases the company profitability metrics. While attempting to have a predictive churn model, it is important to define and understand what is churn for the company. Churners can be voluntary or involuntary. However, a clear distinct is important.
Scope
To begin with, the scope of the project will be based on prepaid deliberate churners. This subscriber base experiences the highest churn rate. In this category as per (Santharam and Krishnan, 2018), there can be incidental and deliberate churn. Deliberate churn occurs due to number of reasons which can be related to price, competitor’s offerings, quality of service, number of incidents. Incidental churners are those who leave due to some location changes or financial position.
Model Aim
The aims will be to identify the churners who will potentially stop using the service/product after some time. The time definition is important here so that the track records (CDRs) and other information can be used. In the current context, the churn prediction will be for the forthcoming two months. During period, the company has ample time to work on the retention period and try to reassess the prediction model.
Once the predicted data is available, the potential churners will be clustered based on different parameters. Out of these parameters some of them are: number of call drops, number of wrongly billed clients, number of complaints, number of rejected SMS, number of failed payments, competitors’ price etc.
Over this clustered information, the AI recommender system will work towards providing recommendations for retention of the customers. For example, what products/services can be optimized to solve the issues encountered by the client. Besides, there can be priorities set in this recommendation system based on the number of clients in each of the cluster identified or based on revenue generation.
As a final step, the aim is to improve the predictive model by using the retention rate obtained as defined below:
Contribution towards sustainability
In Mauritius, most of the sim cards are plastic/electronic base. The project also aims to reduce the emission of these small electronic and plastic items by allowing clients to make use of it for a maximum duration which in term will reduce the plastic emission in our environment.
Literature Review
Several researchers have tried to solve the churn problem and use multiple techniques for recommender systems (Table 1). According to Weber and Schutte (2019), the use of marching learning is both practical and highly developed. According to Ammari (2022, p.317) and Sharma et al. (2022), artificial intelligence has become an integral part of marketing and social customer relationship management in this era of Web 4.0. For instance, Carrefour and Sirgul recently launched a small retail shop which relies on artificial intelligence to personalize the customer experience, reposition products, reduce food spoilage and provide real-time alerts (Zabala, 2018).
A decision tree model makes use of R programming to build a churn prediction model. (Bhadoria and Mathur (2018)) showed that with a decision tree model, churn prediction is better than the logistic regression model. The accuracy of the confusion matrix shows that the Decision Tree model outperformed the Logistic regression. Even (Dahiya and Bhatia, 2015) confirm that the decision tree performs better than the logistic regression technique. However, (Alamsyah and Salma (2018)) added another algorithm of Random Forest for the predictive analysis of the previous two algorithms. Based on the experiments, they concluded that random forest has a better accuracy of 97.5% and is more reliable for this kind of prediction. (Ahmad et al. (2019)) used four different algorithms, out of which the best accuracy results were from XGBOOST algorithms (93.3%). With 10-folds cross-validation, the experiment was performed. Though there were issues with the dataset, like an unbalanced dataset, they were tackled accordingly by methods like under-sampling. (Idris and Khan (2012)) proposed a genetic programming model with an AdaBoost-based methodology, which was advantageous for the forecast.
Churn Prediction
Some efforts by companies have proved retrogressive in maintaining their users. For example, Ascarza et al. (2016) carried out an experiment which revealed that recommending prices to customers can increase the number of potential churners from a system. While having customer churn prediction is good, it is even better to have a recommendation AI-based system that can help retain the potential churners. In this regard, Sree Buddha College of Engineering and Renjith (2015) proposed a model which is related to E-Commerce customer churn. The model firstly builds a forecast of churners; then, it uses clustering algorithms (K-Means and hierarchical clustering) to form groups based on their profile and behaviour. Lastly, the AI-based recommender system uses a collaborative filtering mechanism to recommend actions for the potential churners in the Business Customer (B2C) environment.
There are researchers who have used hybrid models to predict customer churn likelihood. Renjith (2017) proposed a framework founded on a support vector machine to help predict E-commerce customer churn. The author also proposed a hybrid recommendation strategy to suggest personalized retention actions. Dingli et al. (2017) demonstrated how a business could utilize its transactional data features to predict churn in the retail industry. The researchers demonstrated how extracting and analyzing data available within the Point of Sales systems can help in predicting customers’ buying patterns. The researchers obtained their data from a local supermarket, which they used to identify the churners using Convolution Neural Networks and Restricted Boltzman Machine learning techniques. The Restricted Boltzmann Machine achieved 83% accuracy in predicting customer churn. In another study, Ullah et al. (2019) proposed the use of the Random Forest (RF) algorithm, a classification and clustering technique to identify customers that churn, to predict the factors leading to their churning using information correlation and gain attribute ranking filler. The RF correctly classified the churning instances in 88.63% of the cases, proving slightly better than the Restricted Boltzmann Machine Learning Techniques at predicting customer churn.
Restricted Boltzmann Machines for Collaborative Filtering was one of the first related approaches in the neural network literature. Lin and Gao (2021) proposed a two-headed transformer-based network to predict unlocked sessions and to predict user feedback through multitasking with click behaviour prediction, session-aware re-weighted loss, and randomness-in-session augmentation. The method attained a categorization accuracy of 0.39224 on Kaggle. Hidasi et al. (2015) proposed an RNN-based technique for session-based recommendations that is able to model an entire session instead of basing recommendations on short session data. The model also introduced modifications to classic RNNs by introducing aspects like ranking loss function. Tan et al. (2016) proposed the application of two techniques for the improvement of RNN-based models for session-based recommender systems: data augmentation and a method for accounting for shifts. Sheikhoushaghi et al. (2022) proposed an RNN for oil forecasting. In a more recent paper, Wang et al. (2015) offer a more general technique in which a deep network is used to extract generic content features from all sorts of objects. Then these features are put in a typical collaborative filtering model to improve the recommendation performance. Situations with insufficient data on how users interact with products seem to benefit most from this strategy. Saias et al. (2022) proposed a churn risk prediction system that can help cloud server providers recommend adjustments at the service subscription level to avoid CSP customer loss and promote rational resource consumption. The researchers built a training data set from customers’ data, the service they subscribed to, and their usage history to predict churning trends using a machine-learning approach. The researchers built and evaluated classification models based on AdaBoost, multilayer neural networks and random forest algorithms. The forest-based model produced the churn prediction results, having 0.997 AUC value and a 0.988 accuracy, with 64 estimators.
Recommendation Systems
Recommendation systems are very important and are applicable in various online supported industries. Lü et al. (2012) highlighted the importance of the recommendation systems, noting that they have a great scientific depth emanating from different research fields. According to Singh et al. (2021), the online marketing recommendation tools help ease a user’s work by presenting them with the exact product they are searching for or products they can consider as alternatives. Some of the most popular techniques identified by the researchers include collaborative filtering, data mining algorithms like WebMining, and the use of the if-then statement, also known as the association rule. Another important technique for recommender systems is graph neural networks which entail high order connectivity, enhanced supervision signal, and structural property data (Gao et al., 2022).
One of the most vital fields of study in AI is text mining. Masood and Raha (2021) explained text mining, also known as text analytics, as a subfield of AI that makes use of natural language processing (NLP) to organize and normalize the free (unstructured) text included in documents and databases so that it may be analysed or used on machine learning (ML) algorithms. According to Hassani et al. (2020), text mining may be used to find insights, information, relationships, and claims that would otherwise be buried in big textual data. After the data has been sorted, it is structured for graphical representation in the form of clustered HTML tables, mind maps, and charts for further analysis and presentation. Text mining relies heavily on natural language processing (NLP) tools to process incoming text (NLP). Databases, data warehouses, and BI dashboards may all benefit from the addition of structured data obtained by text mining for descriptive, prescriptive, and predictive analytics. Emulating the human ability to understand a natural language like English, Spanish, or Chinese, Natural Language Understanding may help machines “read” text (or another input like speech). NLP and NLG are subsets of Natural Language Processing, which aim to replicate the human ability to understand and generate written text in natural language for purposes such as summarizing data or carrying on a discussion.
Natural language processing (NLP) has developed over the last decade to become a mainstream technology utilized by widely adopted applications like Siri, Alexa, and Google Voice Search to understand and respond to user requests. Modern text mining techniques have aided researchers in many fields, including healthcare, business (risk management), customer service (fraud detection), and contextual advertising. According to Mach-Król, et al. (2021), it is important to highlight the idea of customer insight regarding the relationship with these notations since these ideas have been structured and prioritized many times; scientific works show this from the previous century in the area of information understanding. Knowledge about consumers that is valuable, unique, difficult to mimic, and which the company is aligned to utilize gives it a competitive advantage.
Creating or extracting value from customer insights was a challenge in the 21st century for the enterprise. Mach-Król et al. (2021) proposed a framework with 12 successive stages to correctly extract value from customer insights. One of its most important elements is to listen to consumers and properly develop the proposed changes. A company should avoid deciding what change is most needed for its proper development based on its preferences. He also demonstrated that listening to consumers may disclose important information by gathering their insights and evaluating them. Song et al. (2016) proposed a deep neural network-based architecture that can model short-term temporal and long-term user preferences to improve the performance of recommendation systems. The researchers proposed a novel pre-train method to train the model efficiently for large applications by significantly reducing the number of free parameters. The resulting model was applied to a commercial News recommendation system’s real-world data set. The model significantly outperformed the state-of-the-art when compared with established baselines in experiments.
There are many machine learning techniques that have been used in the telecom industry to help with churn prediction. Liyanage et al. (2022) used machine learning techniques like artificial neural networks and k-nearest neighbors and deep neural networks (DNN) to analyze 21 attributes of 7000 post-paid subscribers of a telecom company. The researchers found that the long short-term memory networks (LSTM), a DNN, produced better results than the machine learning algorithms with an accuracy rate of 82.46%, making it the method of choice for creating the company’s final churn prediction model. Gharaei et al. (2021) proposed a content-based clothing recommender system using a deep neural network which eliminates the need to manually extract product features required to predict unobserved item ratings. It is a unique system that incorporates gender specifications as a feature in suggestion-making important demographic information. From the experimental results, the loss of the proposed system is lower than other baseline systems, helping in resolving the cold start challenge faced by new items. It also recommends new, relevant, and unexpected items.
It is possible to model the behavior of online users with respect to the time they spend on a platform. Wu and Yan (2017) proposed a list-wise deep neural network-based architecture for modeling online user behaviors within each session. The model was first trained using an embedding method that pre-trains a session representation by incorporating user behaviors like views and clicks. The researchers then proposed that the learnt lesson be used to create a list-wise ranking model, generating a recommendation result for each session of an anonymous user. They used quantitative experiments on an e-Commerce company to validate the results, revealing that the list-wise deep neural network performed better than state-of-the-art.
One benefit of deep learning is that it can automatically extract characteristics, which helps to both eliminate the need for clumsy artificial screening features and boost the quality of prediction models. Aşiroğlu et al. (2019) developed a cloth recommendation system that uses a single photo of a user to recommend to them clothe options without having to trace their previous shopping activities or digital footprints using CNN. The system had the following accuracies: color prediction was 98%, gender accuracy was 86% and cloth pattern prediction was 75%.
For the time being, deep learning has proved effective in areas such as image classification, voice recognition, network situational awareness, and high-dimensional time series modelling. According to Geetha and Renuka (2019) the tailored recommendation is a popular area of study and application for deep learning. An AI-powered collaborative filtering method was suggested in the literature. Information from the project side is encoded using the noise side automated encoder; the Person similarity score is then computed; the time SVD++ score is then added, and the final score value is the sum of the two.
Fake users can be a head-ache to online platforms, causing system poisoning. Wu et al. (2021b) proposed the adversarial poisoning training (APT) that simulates the poisoning process, injecting ERM (fake users), dedicated to minimizing empirical risk for the sake of building a robust recommender system. The APT also estimates the influence of each fake user on the empirical risk. APT outperformed baseline models in real-world dataset poisoning attacks, showing its robustness. It also improved the model generalization in most of the cases during the experiments. Lin et al. (2020) studied the shilling attack on recommender systems. They proposed the Augmented Shilling Attack framework (AUSH) with the ability to tailor attacks against RS according to complex and budget attack goals that target a specific user group. The researchers demonstrated experimentally that the framework’s attack was noticeable in diverse RS, based on either modern or deep learning RS. In contrast, the state-of-the-art attack detention model could not detect it.
Guo et al. (2017) proposed an item-based top-N recommendations model that works by learning the item-item similarity matrix, a product of two low-dimensional latent factor matrices learned through the structural equation modelling approach to handling sparse datasets. Experimental results on datasets showed that the model outperformed baseline top-N recommendation models, with the relative performance gains increasing as data becomes sparse. These findings corroborate the experimental results of Kabbur et al. (2013). Another study by Munemasa et al. (2018) proposed deep reinforcement learning based recommender system that uses a multilayer neural network for updating a data’s value function to handle sparse datasets.
According to Zhang et al. (2019), deep learning has become the choice for recommender systems due to its effectiveness in retrieving information in recommender systems research. Covington et al. (2016) reviewed YouTube, a large-scale and highly sophisticated industrial recommendation system and found how deep learning has brought dramatic performance improvements. The site uses a two-stage information retrieval dichotomy of a deep candidate generation model and a deep ranking model, underscoring the importance of deep learning in recommender systems. In their study, Rahmani et al. (2022a) found out that the definition of disadvantaged/advantaged user groups played a vital role in making the fairness algorithm and improved the performance of base ranking models in fairness-aware recommender systems.
There are models that have been created for the sake of collecting free-text data. (Tarnowska et al. (2020)) proposed a recommendation system to collect feedback from customers in free text format. Thus the authors base their research on working with unstructured data. In future work, sequential pattern mining has been proposed to be researched in the customer attrition problem. Naghiaei et al. (2022) proposed an optimization e-ranking approach that seamlessly integrates fairness constraints from the producer and consumer sides in a joint framework. The proposed approach was tested against eight large-scale data sets. It showed that it could improve producer and consumer fairness while maintaining the overall recommendation quality. This algorithm has an important role to play in minimizing data biases.
There are certain scholars who have preferred hybrid systems for their robustness in giving results. Saravanan and Sathya (2019) proposed a hybrid feature extraction method involving t-Distributed Stochastic Neighbor Embedding (t-SNE) and Principle Component Analysis (PCA) with Support Vector Machine (SVM) to isolate and list online products according to the product’s high positive reviews. The researchers predicted that the proposed method would have the complexity, recall, accuracy, and precision necessary for the system’s entire accurateness. Abdulla et al. (2019) proposed a personalized size recommendation system to predict appropriate users size based on the product data and their history. The system uses a skip-gram-based Word2Vec model to embed users and products in size and fit space and employs the GBM classifier to predict fit likelihood. Nevertheless, this system is still inferior to other content-based recommendations that exploit recurrent neural networks. One of those systems is the one proposed by Suglia et al. (2017), which entails a deep architecture adopting Long Short Term Memory (LSTM) networks that represent the user preferences and the terms to be recommended.
The nonlinearity attentive similarity model has also been modified to enhance recommender systems. Shan et al. (2019) proposed a nonlinearity attentive similarity model (NASM) using locally attentive embedding for item-based collaborative filtering (CF), based on the neural attentive item similarity (NAIS) model. The researchers introduced novel non-linear attention and location to simultaneously capture global and local items’ information. Compared with the other state-of-the-art recommendation models, the NASM attained superior performance in normalized discounted cumulative gain (NDGC) and hit ratio (HR). Lamche et al. (2014) also proposed a shopping recommender system that combines critiquing and active learning for the exploratory mobile context. According to the results from the test, conversation Active Learning improves the user’s experiences. One of the weaknesses of a collaborative topic regression (CTR), which learns from users’ ratings for items, and item content information, is that the latent representation it learns may be ineffective when the auxiliary information is sparse. Wang et al. (2020) proposed a hierarchical Bayesian model called deep collaborative learning (CDL). The CDL can perform deep learning for the content information and the collaborative filtering feedback matrix. Experiments showed that CDL has a significant potential for advancing the state-of-the-art.
The Bayesian model has also been used in modelling social networks. Purushotham et al. (2012) proposed a variant of the hierarchical Bayesian model that incorporates probabilistic matrix factorization and topic modelling of social networks to help predict the user’s ratings of items. The experimental results showed that the algorithm provided a more effective RS than the state-of-the-art approaches. Nosratabadi et al. (2022) comprehensively investigated the state-of-the-art using hybrid deep learning models, ensemble models and hybrid machine learning models and their application in marketing, stock market, e-commerce, cryptocurrency and corporate banking. The study revealed that hybrid models outperform other learning algorithms, availing the possibility of the emergence of complex hybrid deep learning models. In another study, Wu et al. (2021a) proposed triple adversarial learning of discriminator, influence module, and generator (TrialAttack). It is an end-to-end flexible poisoning framework that generates harmful and non-notable user profiles by generating malicious users from input noise via its triple adversarial learning model. This model outperformed state-of-the-art attacks, generating fake profiles that are very difficult to detect.
Q & A sites
Question answer sites are very important interactive platforms. According to Roy et al. (2022), community question-answering sites (CQAs) have generated a lot of discussion in recent decades. According to the review, the major research themes revolved around the question answer quality and expert identification. Moreover, the most widely studied platforms are Yahoo! Answers, Stack Overflow and Stack Exchange. In general, the study of the application of machine learning outweighs that of deep learning though the latter is on an upward trajectory. Dror et al. (2012) developed a model to predict the behavior of yahoo users during their first week of activity, focusing on their rate of activity, personal information and social interaction with other users. The model showed that the asker’s positive responses and thumbs ups and the count of best answers were the most vital signals for the number of answers a user would give. On the other hand, Pudipeddi et al. (2014) proposed a model that uses the first k posts or the first T days of a user’s activity to identify the factors leading to the churning of newcomer users in the early stages and veterans in the later stage in a Q and A site. The researchers identified a time gap between subsequent posts’ most important factor for diminishing user interest. These findings are consistent with Yang et al. (2019) review of literature on Community Question Answering (CQA) recommendation systems which found contradictory and conflicting research results and research gaps in the literature review.
E-commerce
Many scientists have proposed various models for e-commerce platforms. Suresh et al. (2014) proposed an aspect-based recommendation system that extracted specific review ratings and recommended user reviews based on the user’s and fellow users’ rating patterns. Alexandridis et al. (2019) proposed a new technique of incorporating user reviews into a collaborative filtering matrix factorization algorithm using the Paragraph Vector Model. The neural embedding was then used with the rating scores in a hybrid probabilistic matrix factorization algorithm using the maximum a-posteriori estimation. This idea was proved to be robust since it outperformed three baseline methods when their performance was assessed.
Fashion Recommender Systems
The fashion industry has a variety of recommender systems. Pereira et al. (2022) reviewed customer models (CMS) for AI based decision support systems in the fashion e-commerce supply chains. He and Hu (2018) developed FashionNet, DNN based personalized outfit recommendation. Deldjoo et al. (2022) reviewed modern fashion recommender systems. They identified outfit recommendation, size recommendation, explainability, users, items and context, among the challenges experienced in applying deep learning in the sector. Also, the researchers identified outfit recommendation, pairing recommendation, outfit generation, and fill-in-the-blank outfit compatibility prediction as the most important evaluation goals. Grbovic et al. (2015) proposed a novel neural language-based algorithm that leverages a user’s purchase history from e-mail receipts to deliver highly personalized advertisements to Yahoo Mail users. There was a 9% increase in click-through rates for the ads, which were in the form of product recommendations. Besides the improved online traffic, the algorithm considerably increased the lift conversion rates.
E-commerce platforms have further generated much interest from researchers. Agarwal et al. (2018) proposed a mixed approach for personalizing similar product recommendations for customers in e-commerce platforms in the fashion industry, where customers are recommended personalized similar products. The experimental results demonstrated that such a method could improve the key metrics used in personalizing similar product recommendations. Wu et al. (2016) proposed a personalized recommendation model that integrates RNN with Feedforward network, representing a use-item correlation for improved prediction accuracy. When the researchers tested the model over Kaol, an e-commerce website, it showed significant improved compared to the baseline recommendation service. According to Cardoso et al. (2018), the addition of new products to the catalogue of e-commerce platforms makes it challenging to personalize customer experience, forecast product demand and plan product range. The researchers proposed that the platforms should have consistent and detailed information for each product, which can be leveraged through quantitative analysis to improve a hybrid recommender’s recommendations. Mohammadi and Kalhor (2021) propose that retailers and consumers in the fashion business may reap the advantages of artificial intelligence, machine learning, and computer vision. As a result, the field of artificial intelligence (AI) applications in the fashion industry continues to grow. AI is expected to radically transform the fashion sector into smart fashion shortly.
Here, we examine this sensitivity in recommender systems, where even little changes in the behaviour of seemingly unrelated users may significantly impact the suggestions given to those users. Oh and Kumar (2022) proposed prediction models to be sensitive to changes in the training data, leading to inconsistent forecasts for individual data points when the model is put to the test. List Sensitivity (RLS) is a stability metric for recommender systems that evaluates the variation in test-time rank lists produced by a recommender system in response to a change in the training data. Using the cascading effect, Oh and Kumar (2022) determined the minimum and systematic perturbation needed to produce maximum instability in a recommender system, a technique called CASPER. Based on experiments conducted with four datasets, it is clear that recommender models are too susceptible to random or CASPER-introduced tiny perturbations. Slightly altering one random interaction of one user has a large effect on the suggestion lists of all users. Importantly, with CASPER perturbation, low-accuracy users (those who obtain poor quality suggestions) receive more unstable recommendations than high-accuracy users.
In published research and online, matrix factorization and neighbourhood models are commonly employed. Campo et al. (2018) developed a Collaborative (Deep) Metric Learning (CML) for predicting the purchase of new movies. Faisal et al. (2019) proposed, developed and test a deep neural networks recommendation engine for movies to address cold case scenarios. The model recommends movies to users based on their preferences. The model was more accurate than the traditional ones, providing personalized movies recommendation to customers. Donkers et al (2017) proposed an extension of Recurrent Neural Networks that takes into account some of the special features of the Recommender Systems domain. Donkers et al (2017) demonstrated how users, along with sequences of consumed items, can be represented in a new type of Gated Recurrent Unit (GRU) to effectively generate personalized next-item recommendations. Results from offline experiments on two real-world datasets show that, compared to state-of-the-art recommender algorithms and a standard Recurrent Neural Network, the extensions significantly outperformed the baseline models.
Another popular deep learning algorithm is the deep learning convolutional network. Hu et al. (2018) proposed a promotion recommendation technique and system based on random forest that can analyse a user’s historical mobile data usage, as well as their profiles, for the purposes of designing sales, marketing and recommendation strategies for telecom operators. Experimental results show that the method was 93.36% accurate, which is higher than the traditional techniques. Bouneffouf et al. (2012) proposed an algorithm that tackles the issue of content evolution in Mobile Context-Aware Recommender Systems, which is based on the aspects of exploration and exploitation, adapting to either after deciding the user’s situation best adapted to them. The researchers tested the system in a deliberately designed offline simulation framework, and their algorithm outperformed the baseline algorithms.
The popular e-commerce user recommendations rely on user attributes like purchase history or user profiles, which may not be applicable in the case of drive-thru recommendations. Wang et al. (2020) proposed the Transformer Cross Transformer (TxT) model, which utilizes a user’s order behaviour and contextual features like weather, time and location for drive-thru restaurants. This model achieved superior results in drive-thru production compared with the baseline recommendation solutions. The researchers were able to run deep learning workloads and end-to-end big data analytics on the same data and the model proved generalizable to other interaction channels.
Li et al. (2017) proposed the framework of a neural network called the Neural Attentive Recommendation Machine (NARM) to generate recommendation results from short sessions. Using a hybrid encoder with an attention mechanism, they could model the user’s sequential behaviour. Also, the hybrid encoder captured the user’s main purpose in the current session. Using a bi-linear matching scheme, the model then computed the recommendation scores for each candidate item. Experimental results show that NARM outperformed state-of-the-art baselines on both items. Also, it attained significant improvement during long sessions, demonstrating its advantages when it comes to simultaneously modelling a user’s main purpose and sequential behaviour. Twardowski (2016) proposed a Session-Aware Recommender System model that eliminates the need for any straightforward user information but only relies on the user activity with a single session, defined by a sequence of events. The model uses Recurrent Neural Network (RNN) and explicit context modelling with factorization methods to incorporate information into the recommendation process. The RNN-based model performed better than the session modelling approach, directly modelling the user dependency observed sequential behaviour in its recurrent structure.
A user session begins when a user clicks on an item; inside a user session, the user clicks on the fascinating item and spends more time examining it. The user then clicks on an alternative preview image to refresh the website. These cycles will continue until all requirements of the user have been satisfied. Existing recommendation algorithms struggle when recommendations are based on only those user sessions, so this creates difficulty for current recommendation models. As a workaround, Li et al. (2017) proposed a session-based model, which tracks a user’s actions in the current session to infer what they may be interested in next. Recurrent neural networks (RNN) with Gated Recurrent Units (GRU) are used for session-based recommendation.
According to Quadrana et al. (2017), session-based recommendations are very relevant to e-commerce, video streaming and other recommendation settings. The Recurrent Neural Networks have proved to be robust performers in session-based settings. Even though it is not easy to come by session-based recommendation domains, the user profiles of some domains are readily available. Quadrana et al. (2017) proposed a way of seamlessly personalizing RNN models with cross-section information transfer to improve session-based recommendations. The researchers also devised a Hierarchical RNN model able to relay end evolves latent, hidden states of Recurrent Neural Networks across the user’s sessions. These model improvements were tested experimentally and showed large improvement over the session-only Recurrent Neural Networks. These outcomes highlight the necessity to quantify sensitivity in the construction of recommender systems, to allow model creators and end users to select whether or not to adopt recommendations. The RNN can easily be expanded upon and include new data types in chronological order. Because of these characteristics, they work extremely well for producing sequential suggestions.
Novel neural networks architecture dubbed the Neural Attentive Recommendation Machine (NARM). NARM is applied to tackle the problem mentioned above. It is a hybrid encoder with an attention mechanism. It can be combined into a unified session representation, to describe the user’s sequential behaviour and capture the user’s goal in their sessions. Training NARM allows it to adjust its focus to different parts of the scene depending on their relevance. The recommendation scores are then determined using a bi-linear matching method based on the unified session representation of each item in the running. During training, NARM discovers both item and session representations, as well as their respective pairings.
The all-encompassing idea of “customer insight” is often utilized to get to know consumers better. This idea encompasses not just the “traditional” data about consumers (who they are, what they like to buy, etc.) but also the “modern” data about customers’ mental states, motivations, and how those states of mind influence their actions (including purchases). It is possible to delve further into one’s insights by examining one’s unconscious and instinctual attitudes and actions. If the process of managing and processing customer insight is adopted and led appropriately, it may be useful for the firm. In a nutshell, customer insight attempts to identify a company’s audience by answering the questions “how?” and “why?” as well as “who?” (or “what?”).
In e-commerce, the popular User-item Click-Through-Rate (CTR) model used for predicting voucher redemption often overlooks the users’ historical behaviour. Xiao et al. (2021) proposed a Deep Multi-behaviour Graph Network (DMBGN) to improve this aspect of voucher redemption rate prediction. In this model, the User-Behaviour Voucher Graph captures the user-voucher-item relations and the user behaviour before and after the voucher collection is considered, and a Higher-order Graph Neural network is used to produce a high-level presentation. The DMBGN showed improvements in the experimental data set, with 2 to 4% and 10 to 16% AUC improvement over Deep Interest Network (DIN) and DNN, respectively. In another study, Geetha and Renuka (2021) proposed the BERT base Uncased model, a Deep Learning Model, to carry out sentimental analysis of customer review data. In the experimental valuation, the BERT model yielded improved performance with highly accurate prediction compared to Machine Learning methods like Naïve Bayes Classification, Support Vector Machine, and LSTM.
CNN is one of the deep learning algorithms which have been applied in recommender systems. Paradarami et al. (2017) proposed a deep learning-based online recommender system; utilizing the convolutional neural network (CNN) based on the users’ and designers’ preference patterns. The model considers colour compatibility for textile products to recommend patterns and proved effective when tested experimentally. Lee and Jiang (2021) proposed a two-stage hybrid machine learning approach to address customer satisfaction and product experience for predicting customer loyalty. Traditionally, the recency, frequency and monetary value (RFM) only focused on customer behaviour to predict loyalty. Wei (2021) proposed the information recommendation model that uses a collaborative filtering algorithm and resource matrix feedback for recommending online course resources. According to the experimental results, the model was excellent in recommendation efficiency and accuracy.
Music Recommendations Systems
Music streaming is one big industry that has attracted a lot of interested from AI enthusiasts. Schedl et al. (2015) reviewed the application of deep learning music recommendation systems (MRS). The researcher found out that deep neural networks help in the extraction of latent factors of music items for metadata or audio signal. It is also used to learn sequential patterns of music items from listening sessions or music playlists. The latent factors are normally integrated into a hybrid MRS or content-based filtering. Some challenges identified in using deep learning for MRS include lack of transparency, the large variety of evaluation metrics for comparing results between approaches and the lack of established multimodal datasets. Moreover, the MRS is impacted negatively because most research adopts a highly system-centric stance.
The probabilistic model has been applied in music recommender systems. Wang et al. (2012) proposed a probabilistic model called the context-aware mobile music recommendation for daily activities. The model integrates contextual information with music content analysis to offer music recommendations for day-to-day activities. The experimental results revealed that the model and its prototype are excellent in accuracy and usability. Batmaz et al. (2019) reviewed the challenges and remedies of deep learning recommender systems and found out that problems like accuracy, scalability and cold-start are still rampant. Anand et al. (2021) proposed a framework for music recommendations with the ability to provide recommendations by checking the audio similarity features using the convolutional neural network (CNN) and the recurrent neural network (RNN). The researchers proposed the need to find a better deep learning model to help in improving the recommender to help it effectively represent users’ privacy preferences.
There are a variety of music and video recommendation systems in the world today. Wang and Wang (2014) proposed a new model for music recommendation systems based on a deep belief network and a probabilistic graphical model. They unified the two stages of music recommendation to have a model that learns features from audio content and makes personalized recommendations simultaneously. This model outperformed the baseline deep learning-based models in warm–start and cold-start stages. It did not need to rely on collaborative filtering (CF) to work but seamlessly integrated the CF and the automatically learnt features. The model outperformed the traditional feature m-based hybrid model besides improving the CF performance. Jia et al. (2015) proposed an Android background service called Multi-modal learning for Video Recommendation (MVR) that collects user behaviours data and then analyses the user’s preferences based on how they use the Android mobile phone applications. The system then recommends different videos to users based on the graphical model. One of the important features of the model is that it can nalyse the users’ habits and integrate the user’s interests for a recommendation. The model proved superior to multiple baselines on the quality of recommendations, including personalized recommendations.
The probabilistic generative model is also a very promising model in the AI field. Zhang et al. (2022) proposed a bi-level optimization framework incorporating a probabilistic generative model that locates items and users whose interaction data is adequate and has not undergone any significant perturbation to leverage the data to determine fake item-user interactions to prevent data poisoning in recommender systems. The researchers also reversed the recommendation models’ learning process and developed a simple but effective technique incorporating context-specific heuristic rules for handling data perturbations and incompleteness. Experiments on two data sets showed that the recommendation models could achieve better attack performance than baseline approaches.
Netflix is one of the major streaming sites in the world. Gomez-Uribe and Hunt (2015) reviewed Netflix’s recommender system’s algorithms. Some of the algorithms include the video-video similarity (sims ranking), which is used in the Because You Watched (BYW) categorization. Netflix also uses the continue watching ranker algorithm, which focuses on episodic content and nonepisodic content. It also has a trending ranker that identifies videos that become famous in short or long periods. Also, Netflix uses the Top-N video ranker for its Top Picks section. The last algorithm is the personalized video ranker (PVR), which orders video catalogues in a personalized way. Goh et al. (2021) proposed a collaborative preference learning model for a music recommender system based on Random Forest, Support Vector Machine, Logistic Regression, K-Neighbors, Naïve Bayes and Decision Tree. Logistic Regression and Random Forest gave the highest and lowest accuracy scores (18.03% and 8.19%), respectively.
The Point of Interest system is one interesting model that has been considered in at least one study. Rahmani et al. (2022b) studied item-user fairness in the point of interest (POI) recommender systems that provide personalized recommendations to users, helping businesses to get potential clients. The experimental results on the various validation models like CF and contextual models on Gowalla and Yelp showed that the POI has unfairness of popularity bias. They also found out that most of the recommendation models cannot satisfy producer and consumer fairness, showing a trade-off between the two variables due to data biases occurring naturally.
The model recommender system been tested in the restaurant industry with much success. Zubchuk et al. (2022) proposed a language Model recommender system for a kiosk’s shopping cart that combines a neural network-based classifier and a language model as a vectorizer. The researchers’ offline tests revealed that the model performed better than baseline models and exhibited performance which could be compared to the best A/B/C tests models. Cheng et al. (2016) proposed a Wide and Deep learning-deep neural network and wide linear models, combining the benefits of generalization and memorization for recommender systems. After productionizing and evaluating the model on Google Play, the results showed that the model increased app acquisitions significantly compared to deep-only and wide-only models.
Telecom Industry
Several researchers have carried out studies on the application of AI in telecom in the telecom industry. Moura Oliveira et al. (2019) explored the possibility of predicting recommendations in this domain based on feedback obtained. While appreciating the advantages of such an AI system, the authors acknowledge that numerous challenges come along, especially in having data availability for good recommendations. Huang and Techadi (2013) proposed a hybrid model learning system for customer churn prediction in the telecom industry. The model integrated the rule-induction method and weighted k-means clustering with ROC, accuracy and AUC as the indicators of the system’s effectiveness. This model attained not only superior prediction performance against other models but also proved adaptable to various applications. Zhang et al. (2021) introduced a recommendation model for telecom packages that is based on optimized deep forests through decision trees and design continuous window sliding mechanism. The experimental results show that the optimized deep forest performs better than the traditional ones; by 5% of the FI score, and 2% after adjusting the deep forest hyper parameters.
There are some researchers that have used hybrid models in the telecom industry. Praseeda and Shivakumar (2021) proposed a churn hybrid churn prediction made of fuzzy particle swarm optimization (FPSO) and divergence kernel-based support vector machine (DKSVM) to categorize churn customers, an important process in customer relationship management (CRM) in classifying churn customers. The researchers then clustered the customers using a hybrid algorithm of hybrid-kernel distance-based possibilistic fuzzy local information C-means (HKD-PFLICM). The researchers also used the hyperbolic tangent kernel and Gaussian kernel to measure distance. The experimental results show that (FPSO- DKSVM) performed better than the baseline algorithms.
Researchers have also used Cross-Company Churn Prediction (CCCP) in the telecom sector to model churn prediction. Amin et al. (2019) proposed a model for Cross-Company Churn Prediction (CCCP) in the telecom sector using data transformation methods like rank, log, z-score, and box-cox, presenting an extensive comparison that validated the impact of the transformational methods in CCCP. The comparison also evaluated the performance of baseline classifiers like Naïve Bayes and Deep learner Neural net (DP) in predicting churn in the telecom sector using the transformation methods. The experimental results showed that while the transformational methods improved the performance of CCCP significantly, Z-score did not achieve better results. Also, the NB-based CCCP model outperformed on transformed data, while KNN, DP, and GBT performed moderately, and the SRI classifier showed no significant results for the common evaluation measures.
Another model that has become popular in the AI field is the mRMR. Idris and Khan (2012) compared the performances of tree-based ensemble classifiers based on maximum relevancy and minimum redundancy (mRMR), F-score, and Fisher’s ratio-based schemes for features selection, to help in the prediction of churn in the telecom industry. The models were to assist in solving the issue of large datasets, which has been a challenge in churn prediction in the telecommunication industry. The mRMR is superior to F-score and Fisher’s ratio-based model because of its ability to return a coherent and well-discriminant feature set, significantly reducing the computations and helping the classifier to attain improved performance. The researchers evaluated the model’s performance using sensitivity, the area under the curve, and sensitivity. Adaboost, working with mRMR and Rotboost, a rotation forest ensemble, showed great results for churn prediction in the telecom industry compared to baseline ensemble methods.
Since clients may easily move between service providers thanks to mobile technology, customer churn is a major issue for the voice and data telecommunications sector. Almuqren (2021) used passengers’ tweets to determine how satisfied they were with the telecom system’s performance. As a result of consumer discontent and the resulting financial losses incurred by businesses, the proportion of post-paid communications users in Saudi Arabia fell in 2019. Numerous studies have shown a connection between dissatisfied customers and business loss. Telecoms have traditionally measured customer attrition based on historical data. Almuqren (2021) constructed a novel gold standard corpus of Saudi tweets related to telecom industry and a new ASA prediction model for churn prediction and sentimental analysis.
Table 1: Summary of Reviewed Literature
Table 2: Summary of Studys Are Answering the Research Questions
Conclusion
The work done till now doesn’t indicate that there has been researched on at least six different prediction algorithms, which also have an AI-based recommender system to cluster potential telecom churners so that the system can recommend retention actions for the telecom users. This idea also provides a chance to learn about the retention rate after the prediction/recommendation and also track new trends to perform better in reducing the attrition rate in telecommunication.
Methodology
Below is the methodology that can be used for the churn prediction and recommender system. The idea is to have a proper data gathering design.
Dataset
For a prediction model to work, an important step is data identification. Today the data is on several platforms as detailed below:
This information is on different platforms so there needs to be a pre-processing stage where by this information can be centralized and combined for easy access to the software architecture. Besides, the call center information is outsourced and data will be available via controlled channels.
Churn prediction approach
Whist there are several techniques for churn prediction, in this approach, I am planning to cover at least six classification algorithms for the forecast. They are:
- Decision Tree
- Bayesian
- Support Vector Machine (SVM)
- Random Forest
- Nearest Neighbor
- Extreme Gradient Boosting
These algorithms will help in having better accuracy. If needed, they can be used in a hybrid approach and try to bring a more accurate result for the later stage. Once this prediction is done, clustering algorithms like K-Means or Density-based can be used to group the potential churners.
Recommender system approach
Hybrid filtering based model can be used for the prediction of users’ products and services.
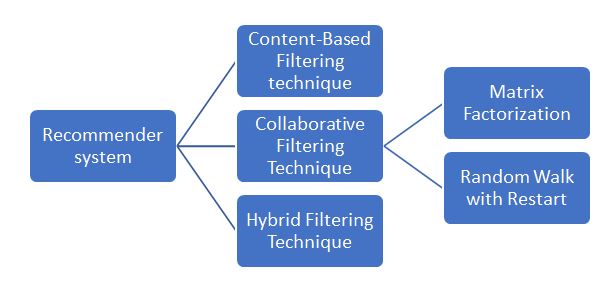
This model combines the content-based and collaborative filtering techniques for better accurate recommendations which combine the current users’ previous track records along with its peers’ current tendency (Wali and Sunitha, 2016).
Methodology flow
Assuming that the data is available, the following methodology can be applied.
Assumptions
As each project has its own assumptions, for this one the following is foreseen:
- Proper approval will be provided by the company for the implementation of the project as there is additional processing of client information in order to increase customers’ satisfaction by making use of artificial intelligence.
- Data set discussed previously is readily available. Even call center information (outside the control of the company) is obtainable via controlled channels
- The retention rate is obtained from business analysis once the recommendation(s) have been implemented accordingly. This information will be fed to the prediction model for it to learning accordingly.
- Software developer will be done in python where all the needed libraries are available.
- Device/Server will have sufficient processing capabilities in order to process the millions of records which are intended to be processed.
- It is assumed that the project start date is as from 15-Jan-2022 and the intended end date is of 30-Apr-2022 making it a project of nearly 3.5 months.
Reference List
Abdulla, M. G., Singh, S. and Borar, S. (2019) ‘Shop your right size: A system for recommending sizes for fashion products’, In Companion Proceedings of The 2019 World Wide Web Conference (pp. 327-334).
Agarwal, P., Vempati, S. and Borar, S. (2018) ‘Personalizing similar product recommendations in fashion e-commerce’, arXiv preprint arXiv:1806.11371.
Ahmad, A.K., Jafar, A., Aljoumaa, K. (2019) ‘Customer churn prediction in telecom using machine learning in big data platform’, J Big Data, 6(28). Web.
Ammari, N. (2022) ‘Social customer relationship management (Social-CRM) in the era of Web 4.0.’, Carthage, p.317.
Amin, A., Shah, B., Khattak, A.M., Moreira, F.J.L., Ali, G., Rocha, A. and Anwar, S. (2019) ‘Cross-company customer churn prediction in telecommunication: A comparison of data transformation methods’, International Journal of Information Management, 46, pp.304-319.
Anand, R., Sabeenian, R.S., Gurang, D., Kirthika, R. and Rubeena, S. (2021) ‘AI based Music Recommendation system using Deep Learning Algorithms’, In IOP conference series: earth and environmental science (Vol. 785, No. 1, p. 012013). IOP Publishing.
Almuqren, L. (2021) ‘Twitter Analysis to Predict the Satisfaction of Saudi Telecommunication Companies’ Customers‘ (Doctoral dissertation). Durham University.
Alamsyah, A., Salma, N. (2018) ‘A Comparative Study of Employee Churn Prediction Model‘, In the 2018 4th International Conference on Science and Technology (ICST). Presented at the 2018 4th International Conference on Science and Technology (ICST), IEEE, Yogyakarta, pp. 1–4. Web.
Alexandridis, G., Tagaris, T., Siolas, G. and Stafylopatis, A. (2019) ‘From Free-text User Reviews to Product Recommendation using Paragraph Vectors and Matrix Factorization’, Companion Proceedings of the 2019 World Wide Web Conference.
Ascarza, E., Iyengar, R. and Schleicher, M. (2016) ‘The perils of proactive churn prevention using plan recommendations: Evidence from a field experiment’, Journal of Marketing Research, 53(1), pp.46-60.
Aşiroğlu, B., Atalay, M.I., Balkaya, A., Tüzünkan, E., Dağtekin, M. and Ensari, T. (2019) ‘Smart Clothing Recommendation System with Deep Learning’, In 2019 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT) (pp. 1-4). IEEE.
Batmaz, Z., Yurekli, A., Bilge, A. and Kaleli, C. (2019) ‘A review on deep learning for recommender systems: challenges and remedies’, Artificial Intelligence Review, 52(1), pp.1-37.
Bhadoria, M.S., Mathur, A. (2018) ‘Analysis of Customer Churn Prediction in Telecom Sector Using Decision Tree’. JASC: Journal of Applied Science and Computations, 5(7).
Bouneffouf, D., Bouzeghoub, A. and Gançarski, A.L. (2012) ‘A contextual-bandit algorithm for mobile context-aware recommender system’, In International conference on neural information processing (pp. 324-331). Springer, Berlin, Heidelberg.
Campo, M., Espinoza, J.J., Rieger, J. and Taliyan, A. (2018) ‘Collaborative metric learning recommendation system: Application to theatrical movie releases’, arXiv preprint arXiv:1803.00202.
Cardoso, Â., Daolio, F. and Vargas, S. (2018) ‘Product characterization towards personalization: learning attributes from unstructured data to recommend fashion products’, In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 80-89).
Cheng, H.T. et al. (2016) ‘Wide & deep learning for recommender systems’, In Proceedings of the 1st workshop on deep learning for recommender systems (pp. 7-10).
Covington, P., Adams, J. and Sargin, E. (2016) ‘Deep neural networks for YouTube recommendations’, In Proceedings of the 10th ACM conference on recommender systems (pp. 191-198).
Dahiya, K., Bhatia, S. (2015) ‘Customer churn analysis in telecom industry’, In 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions). Presented at the 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends).
Deldjoo, Y., Nazary, F., Ramisa, A., Mcauley, J., Pellegrini, G., Bellogin, A. and Di Noia, T. (2022) ‘A review of modern fashion recommender systems’, arXiv preprint arXiv:2202.02757.
Dingli, A., Marmara, V. and Fournier, N.S. (2017) ‘Comparison of deep learning algorithms to predict customer churn within a local retail industry’, International journal of machine learning and computing, 7(5), pp.128-132.
Donkers, T., Loepp, B. and Ziegler, J. (2017) ‘Sequential user-based recurrent neural network recommendations’, In Proceedings of the eleventh ACM conference on recommender systems (pp. 152-160).
Dror, G., Pelleg, D., Rokhlenko, O. and Szpektor, I. (2012) ‘Churn prediction in new users of Yahoo! Answers’, In Proceedings of the 21st International Conference on World Wide Web (pp. 829-834).
Faisal, M., Hameed, A. and Khattak, A.S. (2019) ‘Recommending Movies on User’s Current Preferences via Deep Neural Network’, In 2019 15th International Conference on Emerging Technologies (ICET) (pp. 1-6). IEEE.
Gao, C., Wang, X., He, X. and Li, Y. (2022) ‘Graph neural networks for recommender system’, In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining (pp. 1623-1625).
Geetha, M.P. and Renuka, D.K. (2021) ‘Improving the performance of aspect based sentiment analysis using fine-tuned Bert Base Uncased model’, International Journal of Intelligent Networks, 2, pp.64-69.
Geetha, M.P. and Renuka, D.K. (2019) ‘Research on recommendation systems using Deep learning models’, International Journal of Recent Technology and Engineering (IJRTE), ISSN, pp.2277-3878.
Gharaei, N.Y., Dadkhah, C. and Daryoush, L. (2021) ‘Content-based clothing recommender system using deep neural network’, In 2021 26th International Computer Conference, Computer Society of Iran (CSICC) (pp. 1-6). IEEE.
Goh, B.J., Soong, H.C. and Ayyasamy, R.K. (2021) ‘User Song Preferences using Artificial Intelligence’, In 2021 IEEE International Conference on Computing (ICOCO) (pp. 330-335). IEEE.
Gomez-Uribe, C.A. and Hunt, N. (2015) ‘The Netflix recommender system: Algorithms, business value, and innovation’, ACM Transactions on Management Information Systems (TMIS), 6(4), pp.1-19.
Guo, G., Zhang, J., Zhu, F. and Wang, X. (2017) ‘Factored similarity models with social trust for top-N item recommendation’, Knowledge-Based Systems, 122, pp.17-25.
Grbovic, M., Radosavljevic, V., Djuric, N., Bhamidipati, N., Savla, J., Bhagwan, V. and Sharp, D. (2015) ‘E-commerce in your inbox: Product recommendations at scale’, In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1809-1818).
Kabbur, S., Ning, X. and Karypis, G. (2013) ‘Fism: factored item similarity models for top-n recommender systems’, In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 659-667).
Hassani, H., Beneki, C., Unger, S., Mazinani, M.T. and Yeganegi, M.R. (2020) ‘Text mining in big data analytic’, Big Data and Cognitive Computing, 4(1), p.1.
He, T. and Hu, Y. (2018) ‘FashionNet: Personalized outfit recommendation with deep neural network’, arXiv preprint arXiv:1810.02443.
Hidasi, B., Karatzoglou, A., Baltrunas, L. and Tikk, D. (2015) ‘Session-based recommendations with recurrent neural networks’, arXiv preprint arXiv:1511.06939.
Hu, W.H., Tang, S.H., Chen, Y.C., Yu, C.H. and Hsu, W.C. (2018) ‘Promotion recommendation method and system based on random forest’, In Proceedings of the 5th Multidisciplinary International Social Networks Conference (pp. 1-5).
Huang, Y. and Kechadi, T. (2013) ‘An effective hybrid learning system for telecommunication churn prediction’, Expert Systems with Applications, 40(14), pp.5635-5647.
Idris, A. and Khan, A. (2012) ‘Customer churn prediction for telecommunication: Employing various features selection techniques and tree-based ensemble classifiers’, In 2012 15th international multitopic conference (INMIC) (pp. 23-27). IEEE.
Jia, X., Wang, A., Li, X., Xun, G., Xu, W. and Zhang, A. (2015) ‘Multimodal learning for video recommendation based on mobile application usage’, In 2015 IEEE International Conference on Big Data (Big Data) (pp. 837-842). IEEE.
Lamche, B., Trottmann, U. and Wörndl, W. (2014) ‘Active learning strategies for exploratory mobile recommender systems’, In Proceedings of the 4th Workshop on Context-Awareness in Retrieval and Recommendation (pp. 10-17).
Lee, H.F. and Jiang, M. (2021) ‘A Hybrid Machine Learning Approach for Customer Loyalty Prediction’, In International Conference on Neural Computing for Advanced Applications (pp. 211-226). Springer, Singapore.
Li, J., Ren, P., Chen, Z., Ren, Z., Lian, T. and Ma, J. (2017) ‘Neural attentive session-based recommendation’, In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (pp. 1419-1428).
Lin, T.H. and Gao, C. (2021) ‘Session-aware Item-combination Recommendation with Transformer Network’, In 2021 IEEE International Conference on Big Data (Big Data) (pp. 5708-5713). IEEE.
Lin, C., Chen, S., Li, H., Xiao, Y., Li, L. and Yang, Q. (2020) ‘Attacking recommender systems with augmented user profiles’, In Proceedings of the 29th ACM international conference on information & knowledge management (pp. 855-864).
Liyanage, R.P.H., Kumara, B.T.G.S., Kuhaneswaran, B. and Prasanth, S. (2022) ‘Deep Learning Approach for Detecting Customer Churn in Telecommunication Industry’, In Social Customer Relationship Management (Social-CRM) in the Era of Web 4.0 (pp. 196-215). IGI Global.
Lü, L., Medo, M., Yeung, C.H., Zhang, Y.C., Zhang, Z.K. and Zhou, T. (2012) ‘Recommender systems’, Physics Reports, 519(1), pp.1-49.
Mach-Król, M. and Hadasik, B. (2021) ‘On a certain research gap in big data mining for customer insights’, Applied Sciences, 11(15), p.6993.
Masood, A., and Raha, K. (2021) ‘An approach to text analytics and text mining in multilingual natural language processing’, Materials Today: Proceedings.
Mohammadi, S.O. and Kalhor, A. (2021) ‘Smart fashion: a review of AI applications in the Fashion & Apparel Industry’, arXiv preprint arXiv:2111.00905.
Moura Oliveira, P., Novais, P., Reis, L.P. (Eds.) (2019) ‘Progress in Artificial Intelligence’, In 19th EPIA Conference on Artificial Intelligence, EPIA 2019, Vila Real, Portugal, September 3–6, 2019, Proceedings, Part II, Lecture Notes in Computer Science.’ Springer International Publishing, Cham. Web.
Munemasa, I., Tomomatsu, Y., Hayashi, K. and Takagi, T. (2018) ‘Deep reinforcement learning for recommender systems’, In 2018 international conference on information and communications technology (icoiact) (pp. 226-233). IEEE.
Naghiaei, M., Rahmani, H.A. and Deldjoo, Y. (2022) ‘Cpfair: Personalized consumer and producer fairness re-ranking for recommender systems’, arXiv preprint arXiv:2204.08085.
Nosratabadi, S., Mosavi, A., Duan, P., Ghamisi, P., Filip, F., Band, S.S., Reuter, U., Gama, J. and Gandomi, A.H. (2020) ‘Data science in economics: comprehensive review of advanced machine learning and deep learning methods’, Mathematics, 8(10), p.1799.
Oh, S. and Kumar, S. (2022) ‘Robustness of Deep Recommendation Systems to Untargeted Interaction Perturbations’, arXiv preprint arXiv:2201.12686.
Paradarami, T.K., Bastian, N.D. and Wightman, J.L., (2017) ‘A hybrid recommender system using artificial neural networks’, Expert Systems with Applications, 83, pp.300-313.
Pereira, A.M., Moura, J.A.B., Costa, E.D.B., Vieira, T., Landim, A.R., Bazaki, E. and Wanick, V. (2022) ‘Customer models for artificial intelligence-based decision support in fashion online retail supply chains’, Decision Support Systems, 158, p.113795.
Pudipeddi, J.S., Akoglu, L. and Tong, H. (2014) ‘User churn in focused question answering sites: characterizations and prediction’, In Proceedings of the 23rd International conference on world wide web (pp. 469-474).
Purushotham, S., Liu, Y. and Kuo, C.C.J. (2012) ‘Collaborative topic regression with social matrix factorization for recommendation systems’, arXiv preprint arXiv:1206.4684.
Praseeda, C.K. and Shivakumar, B.L. (2021) ‘Fuzzy particle swarm optimization (FPSO) based feature selection and hybrid kernel distance based possibilistic fuzzy local information C-means (HKD-PFLICM) clustering for churn prediction in telecom industry’, SN Applied Sciences, 3(6), pp.1-18.
Quadrana, M., Karatzoglou, A., Hidasi, B. and Cremonesi, P. (2017) ‘Personalizing session-based recommendations with hierarchical recurrent neural networks’, In proceedings of the Eleventh ACM Conference on Recommender Systems (pp. 130-137).
Rahmani, H.A., Naghiaei, M., Dehghan, M. and Aliannejadi, M. (2022a) ‘Experiments on Generalizability of User-Oriented Fairness in Recommender Systems’, arXiv preprint arXiv:2205.08289.
Rahmani, H.A., Deldjoo, Y., Tourani, A. and Naghiaei, M. (2022b) ‘The unfairness of active users and popularity bias in point-of-interest recommendation’ arXiv preprint arXiv:2202.13307.
Renjith, S. (2017) ‘B2C E-Commerce customer churn management: Churn detection using support vector machine and personalized retention using hybrid recommendations’, International Journal on Future Revolution in Computer Science & Communication Engineering (IJFRCSCE), 3(11), pp.34-39.
Roy, P.K., Saumya, S., Singh, J.P., Banerjee, S. and Gutub, A. (2022) ‘Analysis of community question‐answering issues via machine learning and deep learning: State‐of‐the‐art review’, CAAI Transactions on Intelligence Technology.
Saias, J., Rato, L. and Gonçalves, T. (2022) ‘An Approach to Churn Prediction for Cloud Services Recommendation and User Retention’, Information, 13(5), p.227.
Saravanan, V. and Charanya, S. (2019) ‘C. E-commerce product classification using lexical based hybrid feature extraction and SVM’, International Journal of Innovative Technology and Exploring Engineering, 9, pp.1885-1891.
Shan, Z.P., Lei, Y.Q., Zhang, D.F. and Zhou, J. (2019) ‘NASM: nonlinearly attentive similarity model for recommendation system via locally attentive embedding’, Ieee Access, 7, pp.70689-70700.
Sharma, R., Rani, A., Kumar, M. and Abrol, S. (2022) ‘Social Customer Relationship Management (S-CRM)’, In Social Customer Relationship Management (Social-CRM) in the Era of Web 4.0 (pp. 228-249). IGI Global.
Schedl, M., Knees, P., McFee, B., Bogdanov, D. and Kaminskas, M. (2015) ‘Music recommender systems’, In Recommender systems handbook (pp. 453-492). Springer, Boston, MA.
Sheikhoushaghi, A., Gharaei, N.Y. and Nikoofard, A. (2022) ‘Application of Rough Neural Network to forecast oil production rate of an oil field in a comparative study’, Journal of Petroleum Science and Engineering, 209, p.109935.
Sree Buddha College of Engineering and Renjith, S. (2015) ‘An Integrated Framework to Recommend Personalized Retention Actions to Control B2C E-Commerce Customer Churn’, IJETT, vol. 27, pp. 152–157. Web.
Singh, S., Anand, A., Choudhury, T., Sharma, P. and Mishra, V.P. (2021) ‘Extensive Review on Product Recommendation Techniques’, Data Driven Approach Towards Disruptive Technologies, pp.549-558.
Song, Y., Elkahky, A.M. and He, X. (2016) ‘Multi-rate deep learning for temporal recommendation’, In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval (pp. 909-912).
Suglia, A., Greco, C., Musto, C., De Gemmis, M., Lops, P. and Semeraro, G. (2017) ‘A deep architecture for content-based recommendations exploiting recurrent neural networks’, In Proceedings of the 25th conference on user modeling, adaptation and personalization (pp. 202-211).
Suresh, V., Roohi, S. and Eirinaki, M. (2014) ‘Aspect-based opinion mining and recommendation system for restaurant reviews’, In Proceedings of the 8th ACM Conference on Recommender Systems (pp. 361-362).
Tan, Y.K., Xu, X. and Liu, Y. (2016) ‘Improved recurrent neural networks for session-based recommendations’, In Proceedings of the 1st workshop on deep learning for recommender systems (pp. 17-22).
Tarnowska, K., Ras, Z.W., Daniel, L. (2020) ‘Recommender System for Improving Customer Loyalty, Studies in Big Data‘, Springer International Publishing, Cham. Web.
Twardowski, B. (2016) ‘Modelling contextual information in session-aware recommender systems with neural networks’, In Proceedings of the 10th ACM Conference on Recommender Systems (pp. 273-276).
Ullah, I., Raza, B., Malik, A.K., Imran, M., Islam, S.U. and Kim, S.W. (2019) ‘A churn prediction model using random forest: analysis of machine learning techniques for churn prediction and factor identification in telecom sector’, IEEE access, 7, pp.60134-60149.
Wali, A.S. and Sunitha, R. S. (2016) ‘Churn Analysis and Plan Recommendation for Telecom Operator’. J4R – Journal for Research, 2(3).
Wang, H., Wang, N. and Yeung, D.Y. (2015) ‘Collaborative deep learning for recommender systems’, In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1235-1244).
Wang, L., Huang, K., Wang, J., Huang, S., Dai, J. and Zhuang, Y. (2020) ‘Context-aware drive-thru recommendation service at fast food restaurants’, arXiv preprint arXiv:2010.06197.
Wang, X. and Wang, Y. (2014) ‘Improving content-based and hybrid music recommendation using deep learning’, In Proceedings of the 22nd ACM international conference on Multimedia (pp. 627-636).
Wang, X., Rosenblum, D. and Wang, Y. (2012) ‘Context-aware mobile music recommendation for daily activities’, In Proceedings of the 20th ACM international conference on Multimedia (pp. 99-108).
Weber, F. and Schütte, R. (2019) ‘A domain-oriented analysis of the impact of machine learning—the case of retailing’, Big Data and Cognitive Computing, 3(1), p.11.
Wei, F. (2021) ‘A method of recommending physical education network course resources based on machine learning algorithms’, Security and Communication Networks, 2021.
Wu, S., Ren, W., Yu, C., Chen, G., Zhang, D. and Zhu, J. (2016) ‘Personal recommendation using deep recurrent neural networks in NetEase’, In 2016 IEEE 32nd international conference on data engineering (ICDE) (pp. 1218-1229). IEEE.
Wu, C. and Yan, M. (2017) ‘Session-aware information embedding for e-commerce product recommendation’, In Proceedings of the 2017 ACM on conference on information and knowledge management (pp. 2379-2382).
Wu, C., Lian, D., Ge, Y., Zhu, Z. and Chen, E. (2021a) ‘Triple adversarial learning for influence based poisoning attack in recommender systems’, In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (pp. 1830-1840).
Wu, C., Lian, D., Ge, Y., Zhu, Z., Chen, E. and Yuan, S. (2021b) ‘Fight Fire with Fire: Towards Robust Recommender Systems via Adversarial Poisoning Training’, In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 1074-1083).
Xiao, F., Li, L., Xu, W., Zhao, J., Yang, X., Lang, J. and Wang, H. (2021) ‘DMBGN: Deep Multi-Behavior Graph Networks for Voucher Redemption Rate Prediction’, In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (pp. 3786-3794).
Yang, Z., Liu, Q., Sun, B. and Zhao, X. (2019) ‘Expert recommendation in community question answering: a review and future direction’, International Journal of Crowd Science.
Zabala, V. (2018) ‘Carrefour and Sirqul launch smart retail store in Taiwan’, Sirqul, Inc. Web.
Zhang, S., Yao, L., Sun, A. and Tay, Y. (2019) ‘Deep learning-based recommender system: A survey and new perspectives’, ACM Computing Surveys (CSUR), 52(1), pp.1-38.
Zhang, Y., Wang, M. and Yu, Y. (2021) ‘Telecommunications package recommendation algorithm based on Deep Forest’, In Journal of Physics: Conference Series (Vol. 2078, No. 1, p. 012014). IOP Publishing.
Zhang, X., Wang, Z., Zhao, J. and Wang, L. (2022) ‘Targeted Data Poisoning Attack on News Recommendation System’, arXiv preprint arXiv:2203.03560.
Zubchuk, E., Menshikov, D. and Mikhaylovskiy, N. (2022) ‘Using a language model in a kiosk recommender system at fast-food restaurants’, arXiv preprint arXiv:2202.04145.