Introduction
The 9th of March, 2016, was a watershed moment in the development of artificial intelligence when the Go champion Lee Sedol was beaten by AlphaGo, a computer developed by Google. While both Go and Chess are two-player strategy board games, the greater number of potential movements in Go and the complexity of assessment make Go the more challenging challenge for artificial intelligence. This made it all the more significant when AlphaGo was declared the clear champion after losing just one game (Bory, 2019). Non-playable characters (NPCs) in video games have their whole behavior predetermined by the game’s AI and cannot be influenced by the user (Darbinyan, 2022). Today, through AI, in-game NPCs learn from their experiences and adjust to new situations with novel and exciting strategies as the game progresses.
This report examines issues concerning three main AI areas for game playing. Firstly, it addresses learning concerns, including machine learning’s role in creating AI systems for computer games. Secondly, it examines the scope of game applications for self-play, the effectiveness of applying deep learning to self-play, and whether or not artificial intelligence can master games via self-play. Ultimately, the report summarizes by reviewing everything from a historical perspective, bringing together all the issues covered.
A brief history of AI Gaming
The demand for the smartest artificial intelligence (AI) is considered vital by gamers nowadays due to the growing complexity of virtual worlds. Almost all games’ AI still relies on a small range of predefined actions, the results of which can be predicted with relative ease by experienced gamers (Millington and Funge, 2018). To achieve this objective, machine learning methods may be used to classify the behavior of game participants. A computer processes a game in two ways: Firstly, it may be engaging in a self-play or continually playing. Secondly, the player and the machine have limited information regarding the game state; each infers the opponent’s action to determine their next move. In other words, this approach involves actively learning from the opponent.
The study of AI has found application in many disciplines. Soon after the introduction of video games, the concept of “game AI” emerged. Developing intelligent playable agents, with or without an embedded learning system, is a major focus of AI for game research. This was the original and, for a while, the primary method that artificial intelligence was implemented into video games. As soon as AI was acknowledged as a discipline, forerunners of computer science penned game-playing algorithms to see whether they could handle problems that generally need human intelligence (Millington and Funge, 2018). The video games of the twenty-first century are quite different from those of the mid-twentieth century due to their expansive open environments, realistic visuals, and compelling narratives. Among the best examples of this is A.S. Douglas’s OXO game.
Douglas programmed OXO, a digital version of the Tic-Tac-Toe game, in 1952. Since he played it on the university’s special gaming computer (EDSAC), nobody outside the institution could access it (Saucier, 2022). In OXO, a human could opt to have the computer execute the initial move or take the initiative themselves. The EDSAC would use a rotary telephone dial for players to input their movements, and a 35 by 15 dot CRT would show the board as shown in figure 1 (Computer History Museum, 2022). Several years later, Arthur Samuel devised reinforcement learning (RL), known today as machine learning, by creating software that learnt to play checkers by competing against itself. Most preliminary studies on game-playing AI centered on traditional board games like Go, checkers, and chess, which are advantageous to operate with since they are easy to express in code and can be emulated extremely quickly (Risi and Preuss, 2020). Artificial intelligence technology allows current computers to perform billions of tasks in seconds effectively.

Learning and Self-play in AI
This section explores the many AI methods that make use of machine learning. Notably the concept of self-play in artificial intelligence, as well as several concrete applications of this technique and their respective consequences. The section details issues relating to learning, self-play, and how current technologies enhanced self-play in AI.
Machine Learning
Machine learning (ML) has many applications, from the automation of routine operations to the provision of insightful analysis. According to IBM Cloud Education (2020), ML is an area of computer science that seeks to mimic human learning through the application of data and algorithmic techniques, to produce more accurate results. Such operations include identification, diagnosis, programming, robot control, and forecasting (IBM Cloud Education, 2020). ML methods are divided into two primary classes: supervised learning and unsupervised learning. Supervised learning uses data samples — in other words, it models the information on current or given input and output, while in unsupervised learning, the data sources are random, and the input data contains concealed tendencies; thus, the outcome cannot be identified (Aery and Ram, 2017). However, recent advancements in machine learning include reinforcement learning, self-supervised learning, support vector machines, artificial neural networks, and decision tree learning. The sole difference between self-supervised and traditional supervised learning is that the labels are automatically applied to the test dataset. Figure 2 below illustrates how these techniques are defined in AI for gameplay.
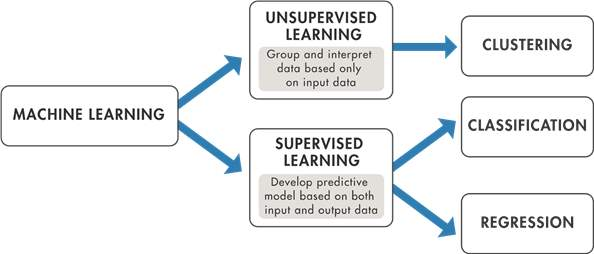
Self-play
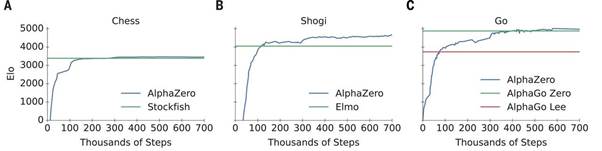
Many researchers have concluded that since system performance is not assured, a full understanding of self-play has not yet been achieved. The term “self-play” describes an artificial gaming system that learns how to play a particular game by watching its copies play instead of being trained by a human operator (Plaat, 2020, p. 195). The AlphaZero algorithm, for instance, attained extraordinary levels of skill in the board games Chess, Go, and Shogi. It used RL to play against itself, where its progress is evaluated using the Elo scale regarding the number of training iterations. Following just 240 minutes (300,000 moves) of gameplay, AlphaZero overcame the stockfish at chess, then expelled Elmo in Shogi after 120 minutes (110,000 moves), and ultimately defeated Alpha Go Lee after 1800 minutes (74,000 moves) in Go (Plaat, 2020). Figure 3 shows the Elo rating of AlphaZero in Chess, Shogi, and Go. The training method recommended maintaining consistency in results over several runs, indicating that AlphaZero’s impressive efficiency is repeatable.
The concept of self-play is intriguing since it promises to free the engineer from having to identify the goal and a fix to a challenge (as it fine-tunes the variables). This degree of independence exceeds what is often considered in research on reinforcement learning. It is counterproductive to train a neural network on oneself since it leads to the roshambo phenomenon. In other words, a winning neural network has been trained by competing against the best outcome from the preceding version. Such a network will formulate a plan Z to overcome tactic Y. Then, a different neural network is trained to learn a tactic that ends up being successful against Z. In situations when there is enough opportunity for training; reinforcement learning can be used.
Integrating temporal difference learning with component approximators is crucial for the effectiveness of RL. In 2015, google Deep-Mind issued a publication claiming they had trained deep neural networks to execute a variety of games on the ancient Atari 2600 video game machine (Krishnan et al., 2021). Every network learned to play a game by being fed just the raw pixel data of the game’s graphics as information, alongside scores, control system directions, and the ability to shoot. Sarker (2021) alludes that Google used deep cue networks to train deep networks, whereby they modified versions of multi-layer Q-learning neural networks. By developing a strategy, they overcome the issues related to using Temporal Difference experience approaches in conjunction with neural networks.
Deep Learning
Artificial neural networks (ANN) serve as the conceptual basis for a subset of machine learning approaches known as deep learning. Supervised learning, unsupervised learning, and reinforcement learning are all types of deep learning. In contrast to deep learning, traditional machine learning methods rely on pre-existing data structures and algorithms, while ANNs are built from the ground up specifically for learning. Figure 4 shows how machine learning differs from deep learning. With deep learning, the input is automatically processed by successive network layers. The development of these neural networks aided AI in numerous contexts, including but not limited to game development, voice assistance, self-learning, and others.
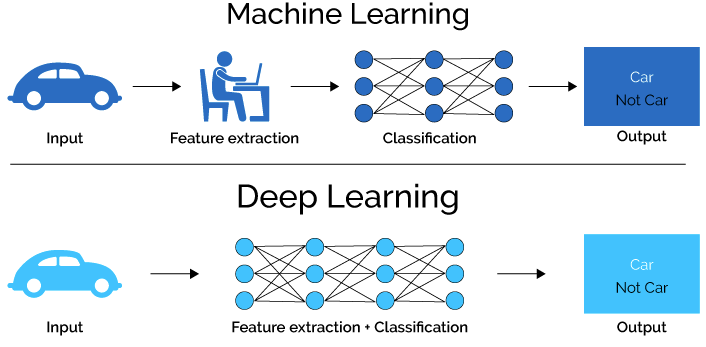
The possible explanation for why deep learning works so well is that it does not rely on human support in data input. In contrast to machine learning, one does not need to grasp what is in the program but instead feeds it raw photos. Deep learning techniques do not need many lines of code to function. They make mistakes and improve via experimentation, progressing at the pace of the computer. The traditional Chinese game of Go is beyond AlphaGo’s comprehension. Go is the perfect game to test AI since it has a scale of 10 out of 170 potential combinations on a surface with 64 squares, which is much more combinations than Chess (Luo, 2020). The makers of AlphaGo first trained the algorithm by exposing it to 160,000 novice games to learn the concept and then gradually gave it progressively more control over the game (Sharma et al., 2019). These findings demonstrate that recent developments in machine learning, including RL, deep learning, and temporal difference learning, have significantly impacted the field of AI’s self-play. In addition to these developments, there have been advances in improving established methods, for instance, self-supervised learning.
Despite the numerous benefits of ML methods and the various achievements in this field, significant obstacles exist to its applications in the gaming industry. The absence of data to draw conclusions from is a huge obstacle in the ML field (Alzubaidi et al., 2021). Since there is scarce reliable historical information on these intricate interconnections, these algorithms must simulate complicated systems and operations. The ML algorithms created for the gaming sector must also be impenetrable. This implies that the systems must be accurate while still being convenient and simple for the user to operate.
Conclusion
The evolution of machine learning methods has significantly affected AI video games. More complicated games that would prolong the fun of games, and possibly new opportunities to improve video game dynamics, are just some of the changes that may be made possible by the increasing importance of AI in the gaming world. The intriguing potential of AI in the gaming business also lies in its excellent analytics skills, which may be subsequently improved to examine player habits and forecast the winning side depending on analytical and ML methodologies.
Reference List
Aery, M., and Ram, C. (2017). ‘A review on machine learning: trends and future prospects,’ Research Cell an International Journal of Engineering Sciences, 25(17), pp.89-96. Web.
Alzubaidi, L., Zhang, J., Humaidi, A.J., Al-Dujaili, A., Duan, Y., Al-Shamma, O., Santamaría, J., Fadhel, M.A., Al-Amidie, M. and Farhan, L. (2021). Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. Journal of Big Data, 8(1), pp.1-74. Web.
Bory, P. (2019). Deep new: The shifting narratives of artificial intelligence from Deep Blue to AlphaGo. Convergence, 25(4), pp.627-642. Web.
Computer History Museum. (2022). Timeline of Computer History. CHM. [online] Web.
Darbinyan, R. (2022). Council Post: How artificial intelligence can empower the future of the gaming industry. Forbes. [online]. Web.
IBM Cloud Education (2020). What is Machine Learning? IBM. [online] Web.
Krishnan, A., Jyothish, N. and Jia, X. (2021). ‘Using reinforcement learning to design an AI assistant for a satisfying co-op experience,’ arXiv preprint arXiv:2105.03414. Web.
Lawtomated. (2019). AI Technical: Machine vs Deep Learning. [online] lawtomated. Web.
Luo, J. (2020). Reinforcement learning for generative art. University of California, Santa Barbara.
Millington, I. and Funge, J. (2018). Artificial intelligence for games. CRC Press.
Plaat, A. (2020). Learning to Play: Reinforcement Learning and Games. Springer
Risi, S. and Preuss, M. (2020). ‘From chess and atari to starcraft and beyond: How game ai is driving the world of ai,’ KI-Künstliche Intelligenz, 34(1), pp.7-17. Web.
Sarker, I. H. (2021). ‘Deep learning: a comprehensive overview on techniques, taxonomy, applications and research directions,’ SN Computer Science, 2(6), pp.1-20. Web.
Saucier, J. K. (2022). ‘The video game age: A brief history’, IEEE Potentials, 41(2), 7-16. Web.
Sharma, S., Xing, C., Liu, Y. and Kang, Y. (2019). Secure and efficient federated transfer learning. In 2019 IEEE International Conference on Big Data (Big Data) (pp. 2569-2576). IEEE. Web.