The Active Remediation algorithm (algorithm 1 – Figure 1) aims to inspect the water service in Flint, Michigan, and identify those lead pipes that need to be replaced by copper pipes. The first step is a Statistical Model that refers to the property data input, including historical records, water test results, and materials observed. After that, the Inspection Decision Rule sets an active learning protocol that randomly selects homes based on the so-called focused exploration. The third step is the Replacement Decision Rule that points to the homes that require pipe replacement.
One should emphasize that the identified steps compose three subroutines that are repeated by the system as data is added. In other words, this algorithm is sequential, which allows making decisions regarding the examination of homes based on data that was received previously. Such an approach is quite accurate: approximately 70 percent of findings pinpoint lead pipes that are potentially dangerous to people since toxic elements may leak into the water supply (Abernethy, Chojnacki, Farahi, Schwartz, & Webb, 2018). The generation of inspections and replacement makes the subsequent data input more comprehensive, narrowing the search of hazardous pipes. Algorithm 1 is a vivid example of machine learning since it uses the existing data to systematically analyze new inputs, and this process is cyclic.

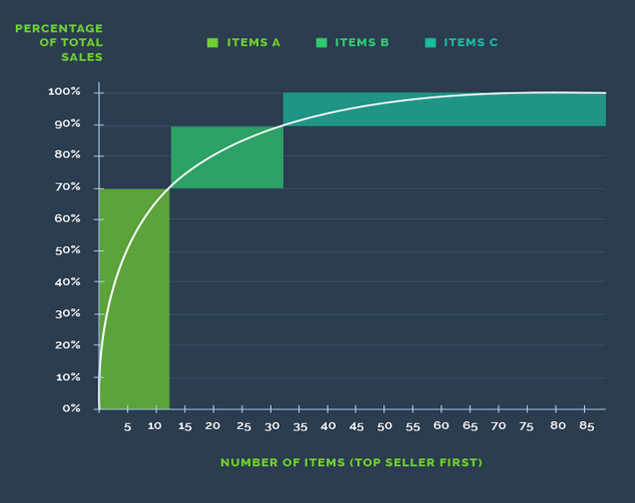
Some uncertainty rate exists due to sampling variation, which should be noted while considering this algorithm. It is important to state that the described algorithm uses the Importance of Weighted Active Learning (IWAL) that is more cost-effective and sensitive to varying parameters compared to other options (Figure 2).
Reference
Abernethy, J., Chojnacki, A., Farahi, A., Schwartz, E., & Webb, J. (2018). Active remediation: The search for lead pipes in Flint, Michigan. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 5-14). London: ACM.