The employment market and related business processes are complex and involve different parties. This is confirmed by the fact that the emergence of new vacancies and new types of employment brings variety and influences the development of trends in this category. The development of information technology and the emergence of innovative mechanisms have brought their own characteristics to the work of companies in the labor market. One of the ways to improve the operational performance of companies and the search for work by people is the introduction of a special technology, which is identified as a recommendation system. The information project, the development of which will be described in this paper, uses recommendation methods to facilitate the selection of a suitable vacancy among people. Using this application, users will be able to obtain the necessary information in a simplified form.
Data Analysis of Employment Market & Job Recommendation System
For both companies and job applicants, text analysis and job discovery tools can become valuable advantages. Monitoring labor market data is critical for detecting and comprehending challenges, as well as the decision-making procedure and weighing the risks and consequences of various employment strategies. The current employment development phase has resulted in a trend of rapid changes in required skills, which might lead to unanticipated outcomes. As a result, both parties exploit information and communication technologies to obtain a competitive advantage on the job market. Text analysis and job trackers, in general, offer a number of advantages for labor market research, namely cost-effectiveness, velocity, accessibility, audience coverage, transparency, and user-friendliness.
An important function of the project is to obtain the data in information technologies job market for data analysis to ascertain valuable information. What concerns the elaboration of a separate and well-functioning recommendation system, it can provide suitable jobs for the user based on their input data. In terms of essential steps identification, the final project can be divided into four parts, including web scraping, data processing, data analysis, and a recommendation system.
The purpose of the project can be defined as the need to collect data from different sources of the job market and combine various inputs and outputs into a large dataset. In addition, one of the important objectives of the project from this particular operational field is to provide figures to the users and customers for knowing the trend of employment market. Nevertheless, the main goal of the final product is determined as the necessity to help different types of users to select a list of suitable jobs in minimal time and efforts. Moreover, the program is designed to help people find their job in one place with the provision of special algorithms assistance. All the processes of choosing preferred jobs with the help of recommendation systems should be efficient, time-effective, and user-friendly.
Methodology
The resources and systems that are involved in the process of finding a labor force, as well as, conversely, finding a job and an employer, work with incredibly large amounts of information. This field of activity provokes the involvement of a large number of people who are looking for work, and a large number of organizations and institutions that need personnel reserves. The labor market and the system for recruiting personnel and finding jobs itself is a sufficiently demanded platform that does not lose its relevance due to the global increase in jobs. In addition, it should be noted that due to the dense concentration of large flows of information, new trends in the development of the sphere appear, which is subject to massive influences. Due to the additional influence of the introduction of new technologies and information solutions on the development of labor market trends, modern approaches are required in the process of collecting and subsequent analysis of information. This project can become a resource that will improve the overall understanding of the labor market and update internal operations.
First of all, the development methods of this project are aimed at interacting with direct users who are seeking job opportunities. The concept of work in this program is built on the fundamental bases of creating recommendations suitable for people, based both on their preferences and on previous experience of interaction. This project is intended to solve the problem of an excessive amount of information and the subsequent large time-consuming method by creating electronic recommendations and lists of suitable jobs. The development of this project will allow users to demonstrate various digital values, as well as visual components in order to explain the main trends in the development of the labor market. To simplify the approach to assessing the benefits of developing this project, it is possible to emphasize the process of solving the problem of complicating the presentation of information and its analysis for users.
Referring to the programming language that was utilized in the process of creating the project, it can be noticed that Python language was selected as an appropriate one. Python is believed to be the world’s fastest developing programming language, due to its simplicity of use, quick learning path, and several high-quality data mining tools (Vallat, 2018). Python has become the software preferred language for data science and analytics applications in research and business (Blank and Deb, 2020). Its vocabulary elements and object-oriented architecture are aimed at assisting programmers in writing concise, rational code for both small and large-scale projects. Python can be considered as the best option for the development of the project since it is generally used in order to finish IT programs rapidly and without unnecessary complications. This technology provides developers with transparent and understandable tools that can be aggregated for the purpose of writing practical codes and making the project user-friendly, well-responding, and customer-oriented.
The question of design, user interface, and layout elaboration should be emphasized since these aspects in creating programs and applications impacts the final perception by customers and users. Dash is considered to be a user interface toolkit for building web-based analytics systems and applications. Dash will be useful to developers and programmers who utilize Python for data processing, information retrieval, visualization, modeling, process control, and reporting. Dash enables creating a graphical user interface for data gathering and analysis scripts simple. The general user interface should satisfy customers’ requirements and facilitate the site’s or application’s efficient and effective functionality. Through juxtaposing graphics, clean design, transparency, and responsiveness, a well-executed general user interface and layout promotes successful interaction between the user and the program, app, or equipment.
In order to generate various useful graphs, charts, and structures for the final project, a software system called Plotly is used. Plotly is a technological computing firm that creates data analytics and visualization applications for the web industry and information technologies sector. Plotly supplies individuals and groups with online graphing, metrics, and statistics capabilities, as well as professional gantt charts and graphical libraries for Python, R, MATLAB, Arduino, Perl, Julia, and REST. In the context of creating visualization elements and graphic objects, this program provides significant assistance, since the final result reflects simplified and understandable schemes. Nevertheless, all critical information is successfully stored, structured and transformed into a visual component. In this project, this feature is important since there is a need to work with large volumes of incoming and outgoing information, which must subsequently be analyzed.
Considering the development tools and techniques that were used for the project elaboration, it is possible to emphasize several methodologies, including web scraping, data processing, data analysis, and recommendation system. Web scraping, also referred to as web gathering or data extraction, is a type of statistical scraping that is used to retrieve information from websites and online platforms (Diouf et al., 2019). While a program user can perform web scraping individually, the word generally relates to automated procedures performed by a bot or web directories (Karthikeyan et al., 2019). It is believed to be a type of duplicating in which particular data is acquired and copied from the internet, usually into a centralized storage, digital document or spreadsheet for retrieval or examination later.
Emphasizing the implementation of this methodology in the project, it is determined to use Scrapy to get jobs details and descriptions from JobsDB and CTgoodjobs. Furthermore, Xpath is utilized to locate corresponding web elements and extract text from different job posting systems. To ensure the correct operation of these processes, it is feasible to directly supply a proxy API key to avoid a potential IP ban from a website and obtain approximately fifteen thousand records in total. Therefore, web scraping is widely used in the final project creation since it provides several useful working features.
The second development tool included in the project elaboration procedures is data processing. The accumulation and adjustment of data elements to generate valuable knowledge is referred to as data processing. It can be regarded as s subset of pattern recognition and information processing in this respect, as it involves the modification of information in any way that can be detected by an outsider. Sophisticated algorithms are required to optimally schedule data processing activities on distributed computing clusters (Mao et al., 2019). The majority of the processing is processed electronically with the help of computers, which means it is done automatically. As for the final product, this technology is used for the purpose of timely collection of information, its verification and conversion into forms necessary for further analysis, including visual.
Using the tools of data processing, it is possible to load separate comma-separated value results, which are delimited text documents with entries separated by a comma, and concatenate into a single data frame. Moreover, with the help of this technology, the analysts will combine columns of the same meaning and replace some wording or symbols to match the format, as presented in the Figure 1. Additionally, the developers will use the natural language processing methodology, a capacity of a software application to comprehend spoken and typed human speech, to remove stop words in job descriptions. Finally, at the stage where all types of data are present, it is feasible to output the processed results to a single comma-separated value file. It can be concluded that data processing, due to a substantial number of auxiliary functions engaged, is an essential technology applied to the project creation process.

Data analysis can be considered as another important development tool and a specific part of the project. The process of examining, classifying, integrating, and modeling data with the objective of identifying usable information, generating judgments, and assisting decision-making is known as data analysis (Rajšp and Fister, 2020). Data analysis has several dimensions and perspectives, including a wide range of techniques under various titles and being deployed in a number of commercial, science, and social science sectors (Assarroudi et al., 2018). Data mining is a type of data analysis that emphasizes statistical modeling and expertise finding for predictive rather than explanatory and descriptive objectives (Yang et al., 2020). At the same time, business analytics refers to data analysis that significantly focuses on aggregation and is primarily concerned with business data.
Data analysis can be classified into three types in empirical applications: descriptive statistics, hypothesis testing, and confirmatory analytical techniques. What concerns the implementation of data analysis and its types in the project, it can be stated that since this technology is crucial in program development, it can receive a high level of prioritization. For the project to comprehend issues and explore data efficiently and effectively, data analysis is critical. This methodology will be used to arrange, assess, structure, and display information in a manner that is meaningful and offers interpretation for the data.
Considering a specific software package or application that is used in the project with the aim of analyzing and process huge amounts of data, Pandas software is utilized. Pandas is a data and statistics transformation and analytics software package for the Python programming language. It includes data architectures and methods for manipulating quantitative charts and time series specifically (Lynden and Taveekarn, 2019). Pandas can extract data from a variety of file types, including comma-separated values, JSON, SQL database records or searches, and Microsoft Excel. The practical advantage of Pandas is described by the possibility to apply various methodologies in data manipulation and assessment, which provides developers and analytics with sufficient information that is beneficial for future decision-making.
Additional software that has to be implemented in the process of the final project creation and development is Scikit-learn. Scikit-learn is a Python-based machine learning and framework library that is free of charge. The Scikit-learn package contains adaptations of a large number of machine learning algorithms that follow a set of standardized data and modeling procedure principles (Hao and Ho, 2019). Furthermore, it provides classification, validation, and clustering techniques, and is intended to function with the Python quantitative and experimental libraries NumPy and SciPy. It uses a Python consistency interface to give a set of effective instruments for machine learning and statistical simulation. The practical value of the Scikit-learn program can be described by the fact that it assists in converting a collection of text documents to a matrix of token counts. This function proves its necessity for the initial extraction of data from text documents and its subsequent transformation into elements that will be used in the data analysis.
Finally, a recommendation system can be highlighted as a development tool and a separate sphere of the project. A recommender framework, also defined as a recommendation system or engine, is a type of data filtration process (Cui et al., 2020). This technology aims to forecast a person’s opinion or preference for particular product or service (Freire and de Castro, 2020). These algorithms can work with a single input, for example, text, or several inputs, for instance, news, books, and search results, inside and throughout platforms. Collaboration filtering and entertainment filtering, often referred to as the personality-based concept, are commonly used in recommendation systems (Ahmed et al., 2021). In addition, other platforms, such as knowledge-based structures, can be successfully implemented. Collaborative filtering techniques create a model based on a user’s previous actions, goods ordered or preferred in the past, or quantitative evaluations provided to those products, and comparable decisions made by other people.
In the situation of the project elaboration, rule-based recommendation systems should be selected in order to provide adjustments to the specific operating field. The website will present over thirty thousand skills and advantages for users to choose. Based on the skills that user input, the program will scan through all the job description and rank the jobs in ascending order; therefore, creating a filtering mechanism. Furthermore, the system should be able to introduce different job features for the user to choose from. In total, for this project type connected to data analysis of employment market and job recommendation systems, a well-structured recommendation engine will provide users with simplified algorithms that will increase individuals’ engagement. Moreover, the ultimate project’s programming language is Python, and XGBoost is an open-source library platform that provides a normalizing gradient boosting architecture for Python. XGBoost is a package for creating high-performance gradient enhancing tree models in a short amount of time. Furthermore, the software library outperforms the competition on a variety of demanding machine learning problems. In terms of the project design and creation, the XGBoost library is used to build the content-based recommendation system.
To create this project and analyze its goals, tasks, and tools, a separate prototype was developed, which included the most necessary information. What concerns the creation and development of the prototype part of the final project, no iterative approach was used. Instead of applying this methodology, it was decided to elaborate the prototype in accordance with a partial system, where all functions are devoted to particular scope of activity. The final prototype of the project was divided into four parts, including web scraping, data processing, data analysis, and recommendation system. These four stages of development of the project were represented by four technologies, which make it possible to develop a recommendation system for the labor market that will work in the interests of the user.
Requirements Analysis
Considering methods used to determine the requirements of the product in terms of satisfying user needs, it can be stated that several activities were produced. One of the methods is described by the fact that users can request to update the list of different job posting websites and additional features they want to implement on the website. Using this method, users can receive large amounts of information from portals that post official vacancies, and analyze it. While reviewing the various job vacancies that will be updated on the website, users will be able to recognize the positive and negative aspects of the job and identify what is missing on the website. In this case, due to the direct involvement of users, it will be possible to accurately define user requirements and specific ways to satisfy them, together with the formation of distinctive features. Furthermore, referring to this technique, it is possible to emphasize the simulation of the real interaction between the user and the system in test mode. In general, some people were invited to test the website as a normal user and the results of this experience were analyzed.
In the subject of online recruiting, development requirements indicate a series of assertions that must be given in the final program. In recent years, online recruiting has regularly confirmed to be one of the most significant advances in hiring strategy (Lewis and Thomas, 2020). As a result, both employers and potential employees have an incentive to make significant use of digital technology such as text mining and job search tools. In this situation, it is possible to specify a number of critical development needs that may also be viewed as major benefits of a job recommendation system and practical solutions to emergent challenges. Variety of tools, cost-effectiveness, accessibility, and user-friendliness are the significant needs.
In terms of tools, the job seeker can use a number of job finding systems to analyze the employment market and discover a suitable position. Text mining-based employment market evaluations were undertaken by one or two researchers with low resources, highlighting cost-efficiency. In the case of job search platforms, users may add filters to eliminate jobs that aren’t right for them. As a result, these technologies cut down on search time while increasing efficiency. In terms of accessibility, text mining mostly makes use of data that is publicly available on job search websites. Similarly, job finding platforms offer similar benefit because candidates can quickly acquire information about open positions and apply immediately. Companies might also contact out to potential candidates or examine competitor job listings. Finally, in terms of user-friendliness, text mining-based research offers a visual depiction of results that makes them understandable to non-academic readers. Furthermore, job finders display vacancy and candidate data in an easy-to-read style, providing the user with concise and systemized information.
Considering non-functional user-requirements, individuals only need to have an up-to-date browser and internet in order to use the website without any obstacles. Also, they can utilize their mobile phones since the application is developed with the help of the ubiquitous computing technology. Emphasizing particular user requirements, which are functional, firstly, the program should keep track of all of an applicant’s information and personal details. This condition is paramount and most important since without the availability of the necessary information, no operations and activities can be implemented. Secondly, the system should allow the individual to make changes to his profile data. Since the field of recruiting is volatile and rapidly evolving, the ability to add new information and edit key features is essential for the correct functioning of the program. Finally, it is possible to mention the requirement that states that users should be able to provide comments on the system and create feedback. In the situation where the system is developed in accordance with the needs of the user, it is necessary to pay attention to feedback and users’ opinion on the operation of the application.
Top Level Design
What concerns the design and the discussion of the major issues, it is possible to relate to the general drawbacks that can occur in the field of online recruitment and job recommendation systems. Despite the multiple strengths and empiric results obtained with text mining and job finder systems, these technologies also have certain limitations. These issues should be considered by employers and potential candidates in order to be able to communicate more effectively. The specific problems, which can seriously impact the productivity, include lack of generalization and technical issues.
In terms of generalization, this is particularly important for text mining analyses of local employment markets. Jung and Suh (2019), for example, stated that their study was focused on a single job search platform, a single location, and a single industry. Similarly, a number of the studies in the review were devoted to examining global patterns on a country scale. As a consequence, their findings should not be generalized to the global employment market or even to the various industries within national markets. In addition, online recruiting may be impersonal, and there are concerns about process management and the accuracy of job postings (Brandão, Silva and dos Santos, 2019). As a result, personal data can be inaccessible for research of the employment market. A difficulty with the length of processed strings may occur from the standpoint of text mining. Longer strings would result in fewer data points that fit the requirements, whereas shorter strings would allow for the processing of higher quantities of textual inquiries at the expense of accuracy.
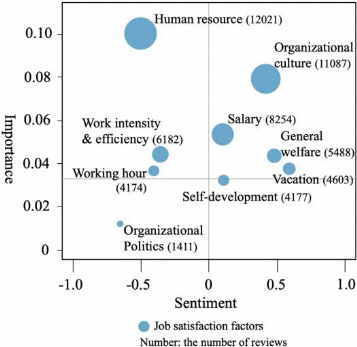
Considering the important aspects of the system, it is essential to highlight the presence of the job satisfaction factors. These aspects, as presented in the Figure 2, illustrate both the basic needs of job applicants and their additional preferences that can potentially influence final decisions. In terms of top-level design, it is extremely important to demand from the employers and companies the inclusion of all the job satisfaction factors. What concerns the test plan, a document that outlines the test approach, goals, and estimates, it can be noted that its elaboration requires thorough examination. This analysis is needed since a job recommendation system has a wide range of metrics and operational fields that have to be documented. In addition, the test plan will require specific deadlines and schedules in order to organize all the examinations.
Conclusions and Reflection
Considering the knowledge extracted from the problem of online recruitment and lack of recommendation systems, it is possible to state that job candidates lack the function of filtering specific job vacancies. Furthermore, they need the ability to select preferable options from lists of potential jobs that illustrate the situation on the employment market. The technology and its application are capable of providing suitable jobs for users based on their input data. In terms of project elaboration, it is important to emphasize the difficulty of dealing with huge amounts of data that have to analyzed, processed, and structured.
With regard to the possibility of having enough time, it is feasible to highlight that more attention should be devoted to the questions of personal data protection and trend prediction. A job recommendation system operates in the employment market and its functions are connected with various types of personal information since job applicants have to provide potential employers with details from their life and experiences. The lessons learned depict the need to establish constant communication with employers to ensure the emergence of new trends on the employment market. With the help of well-structured communication, it will be simpler to anticipate major changes and transformations related to employment relationships.
One should not neglect all sorts of drawbacks and issues happened since the process of creating an IT project provides new skills and knowledge for the developers only via analyzing the shortcomings. With regard to the main problems associated with the development of the project, firstly, the model has been trained on 2000 data points, which cannot be considered as appropriate or perfect. Moreover, a more robust model can be elaborated by increasing the data from 2000 points and more sensible labelling should be implemented, combined with additional training that should be applied to the model. These processes will require lots of time and resources since more data will be received. Furthermore, some columns from different data source are difficult to combine into a large dataset and it requires many types of working activities on the data processing stage. More data sources should be added to the program to increase accuracy and set up a database to store all the data. Finally, the developers should determine specific methodological techniques to increase the velocity of outputting the results from the model.
Reference List
Ahmed, M., et al. (2021) ‘Perception on e-recruitment system in Nigeria’, International Research Journal of Innovations in Engineering and Technology, 5(1), p. 46.
Assarroudi, A., et al. (2018) ‘Directed qualitative content analysis: the description and elaboration of its underpinning methods and data analysis process’, Journal of Research in Nursing, 23(1), pp. 42-55.
Blank, J. and Deb, K. (2020) ‘Pymoo: multi-objective optimization in Python’, IEEE Access, 8, pp. 89497-89509.
Brandão, C., Silva, R. and dos Santos, J. (2019) ‘Online recruitment in Portugal: theories and candidate profiles’, Journal of Business Research, 94, pp. 273-279.
Cui, Z., et al. (2020) ‘Personalized recommendation system based on collaborative filtering for IoT scenarios’, IEEE Transactions on Services Computing, 13(4), pp. 685-695.
Diouf, R., et al. (2019) ‘Web Scraping: State-of-the-Art and Areas of Application’, 2019 IEEE International Conference on Big Data, pp. 6040-6042.
Freire, M. and de Castro, L., (2020) ‘e-Recruitment recommender systems: a systematic review’, Knowledge and Information Systems, 63(1), pp. 1-20.
Hao, J. and Ho, T. (2019) ‘Machine learning made easy: a review of scikit-learn package in Python programming language’, Journal of Educational and Behavioral Statistics, 44(3), pp. 348-361.
Jung, Y. and Suh, Y. (2019) ‘Mining the voice of employees: a text mining approach to identifying and analyzing job satisfaction factors from online employee reviews’, Decision Support Systems, 123.
Karthikeyan T., et al. (2019) ‘Personalized content extraction and text classification using effective web scraping techniques’, International Journal of Web Portals, 11(2), pp. 41-52.
Lewis, A. and Thomas, B. (2020) ‘Hiring the best job applicants?’, Journal of Media Management and Entrepreneurship, 2(2), pp. 19-37.
Lynden, S. and Taveekarn, W. (2019) ‘Semi-automated augmentation of Pandas dataframes’, Data Mining and Big Data, 1071, pp. 70-79.
Mao, H., et al. (2019) ‘Learning scheduling algorithms for data processing clusters’, Proceedings of the ACM Special Interest Group on Data Communication, pp. 270-288.
Rajšp, A. and Fister, I. (2020) ‘A systematic literature review of intelligent data analysis methods for smart sport training’, Applied Sciences, 10(9), p. 3013.
Vallat, R. (2018) ‘Pingouin: statistics in Python’, Journal of Open Source Software, 3(31), p. 1026.
Yang, J., et al. (2020) ‘Brief introduction of medical database and data mining technology in big data era’, Journal of Evidence-Based Medicine, 13(1), pp. 57-69.