Abstract
Infortrack is a start-up company specializing in eCommerce and parcel delivery. The company operates on stand-alone offices distributed in London, Liverpool, Manchester, Bristol, and Chester. The different pickup stations use different data analysis applications such as Microsoft Excel, Statistical Package for Social Sciences (SPSS), and WorkBooks to capture and analyze data. Due to the enormous difference in the final report formats, those at the company headquarters find it difficult to compile the reports. At times, different stations capture data in different formats. This paper presents the challenges faced by the company and presents a technical solution through the development of a data warehouse. The paper begins by presenting a detailed description of the current problems and how they need to be approached. The paper further presents the project management process. Next, it defines the project management process, which is summarized in a work breakdown structure. The paper then presents the requirement gathering and specification analysis. It describes the requirement gathering process and the associated tools. The Database model is then presented, followed by the Extract Transform and Load Data (ETL). The ETL section discusses the FACT and Dimensional tables of the database schema. The report analysis section discusses the achievements of the entire project and how the data warehouse has solved the problems identified in the introduction section. The conclusion presents a summary of the entire report and highlights the advantages and disadvantages of the developed data warehouse.
Introduction
Infortrack is a start-up company specializing in eCommerce and parcel delivery. The company is based in London and has satellite shops and pickup stations within and out of London. The company currently operates in Great Britain but hopes to go international in the next two years. Currently, the company operates pickup stations in Liverpool, Manchester, Bristol, and Chester. The company has partnered with sellers from the cities mentioned above and links them to customers through their eCommerce site. The different pickup stations are strategically positioned and are used as delivery points when customers make orders. Currently, the satellite pickup stations use conventional data management and analysis software such as Microsoft Excel, Statistical Package for Social Sciences (SPSS), and WorkBooks. The stations compile their daily reports, which are then shared with the company headquarters. The data analysis process is complicated and tedious. Often, the company employees struggle to produce the required reports on time. As a result, the company has embarked on developing a centralized database that will store all company data quickly. The data warehouse will be accessed from all offices, pickup stations, and countries. The data warehouse will act as a one-stop-shop for storage, retrieval, analysis, and reporting of company data quickly and effectively.
Introduction to Data Warehouse Design
Unlike the old days, data is currently collected from various sources and in multiple formats. The current technical age is steadily changing and outpacing previous technologies. Business analysis and business intelligence are common tactics in most organizations today, providing experts and management staff with the right tools to help make the best decisions for the organization. Today, organizations collect data from multiple sources and in different formats. With the help of the right and powerful tools within their disposal, business organizations can examine their performance and assess their business positions in the future.
Data warehouse, just as the name suggests, is a vast repository of data collected from business operations, transactions, affiliate sources, and stakeholder databases. A conventional data warehouse is engineered to facilitate easy decision-making processes for experts and the organization’s management personnel. Usually, data warehouses target all employee levels. In a conventional data warehouse, data population is achieved through loading, transformation, and extraction, irrespective of the data source or type. The design and creation of a conceptual data warehouse is a complex process that must pay attention to the structure, type, and requirements of the data sources and the next targets. Data warehouse Incorporated logical, physical, and conceptual models alongside data sources and targets to support end-user data requirements and business goals alike. Data warehousing is built on top of the relational database models. At the end of the day, a data warehouse acts as a one-stop shop for all organizational data, both historical and current.
The concept of data warehousing and data mining are similar, although the two are different technological approaches to management and decision making. The two concepts work on data, although in different phases. Data warehousing compiles data from various processes, sources, and formats, while data mining retrieves meaningful data from the data warehouse. The most crucial point to note is that data warehousing happens before data mining. This means there can be a data warehouse without data mining, while there can not be data mining without a data warehouse.
Usually, data warehousing pulls together data from multiple sources into a single relational or non-relational database depending on company policies. A cooperate organization could pull data from mailing lists, company websites, employee details, cash registers, salary information, and other affiliate sources. Data warehouse provides companies with an upper hand in product research, design and development, product and service forecasting, historical analysis, pricing strategy, and marketing initiatives, and general planning. Data warehouses are usually complex and may be expensive to design, develop and maintain. However, they are always rewarding at the end of the day. As a result, data warehouses should only be designed by experts.
According to Vaisman & Zimányi (2019), different types of data warehousing depend on their purpose. These include data mart, operational data store (ODS), and enterprise data warehouse (EDW). EDW is usually centralized and provides decisive information to all sections of the enterprise. It acts as a one-stop shop for all company data. It also provided department-specific data and reports with respect to the roles and responsibilities of the respective departments. ODS is a real-time data warehouse that provides data when an authentic data warehouse is not required. A data mart is a miniature version of a data warehouse and contains data from specific processes or activities such as sales, marketing, and inventory. A data mart could source its data from multiple points subject to company structure and policy.
Data Warehousing Architecture
The design of a data warehouse is similar to that of a conventional relational database, where it serves as the primary data and information repository. Data warehouse processing activities are different from the processing of operational data. The central data repository is backed up by critical processes and components that are meant to ensure the functionality, accessibility, and manageability of the source data and operational systems. A data warehouse is accessed through user-generated and reporting queries as well as company-specific analysis tools. A standard data warehouse is designed in either of the following three tiers: The bottom tier, middle tier, or the top tier. The data warehouse is usually an enormous relational database accessed via back-end programming and application tools in the bottom tier. The back-end tools carry out all necessary functions such as loading, cleaning, refresh and extracting data. There is an online analytical processing server in the middle tier that acts as a subset of the relational database. In this tier, real-time processing tools implement all processing and analysis operations on company data. The top tier is the simplest of all in that all tools operate at the front end. The tools include data mining, analytics, reporting, and querying tools. The figure below summarizes the data warehouse architecture.
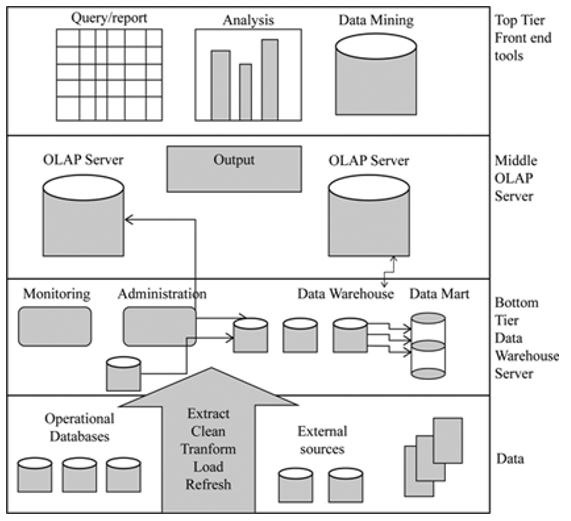
Data warehousing used hardware and software tools to store, retrieve and process data. The tools are generally known as data warehouse appliances and work on all kinds of data. The tools serve one primary purpose: keeping the business organization active in the constantly competitive business environment. The tools provide businesses with a significantly capable DW system. the tools provide the business with intelligent tools to ease their decision-making processes.
The main goal of a data warehouse is to provide an organization with a comprehensive feature of its business operations at any given time. Business intelligence, popularly known as BI, combines methods and tools that convert raw data into reliable formats that can be relied on in business decision-making processes. BI processes act on existing data (in this case, a data warehouse) and include preparation, analysis, and presentation of the data in visual patterns such as charts and graphs. Business intelligence is a game-changer in modern business organizations, providing organizations with fast-tracking tools that help them make quick and effective decisions. BI tools have different capabilities depending on their purpose. Most BI tools are designed to analyze and present data in visual patterns. Just like data mining tools, BI tools work on top of an existing data warehouse. BI is used hand in hand with data analytics to help organizations make the best decisions for success and future existence.
Literature Review
Introduction
This section presents a review of the existing literature on data warehousing technologies, features, industry-specific concepts, types of data marts, and data warehouses. Over the years, researchers have studied different topics on data warehousing and come up with varying results and conclusions. The data warehouse is an essential part of modern information systems design and engineering, database design, engineering, and management and the integration of information systems to existing business systems. As a result, an extensive repository of resources can be used to illustrate the different research methods used to provide a better understanding of data warehouse design concepts. The literature is summarized with respect to the data warehouse design and integration into existing business organizations.
Data warehouse design methodologies
The advent of digital technology and the massive adoption of computers in medium and large-scale organizations has seen the creation, generation, storage, and processing of large volumes of data Moalla(, 2017). Business organizations store data in different formats. The different data types are not related but are jointly used to help the businesses make management, production, and marketing decisions (Dabbèchi, 2020). Usually, the companies store their data in central or separate storage platforms, making it difficult for them to utilize the data for decision-making purposes (ibid). Conventional information processing systems are rarely designed to store or process strategically reliable data. The systems are mainly built to store the most important pieces of data such as management data, employee information, sales and marketing data, operational data, and other crucial information Khouri et al. (2017). In such scenarios, company decisions depend on employee skills set and experience, and historical patterns in company data, which is at times referred to as status quo.
Data warehouses are designed to facilitate access to data in multiple dimensions. Unlike standard relational databases where data is accessed based on particular rules, data warehouse does not limit data access to table structures and relations. Data warehouses are not directly linked to operational databases Golfarelli & Rizzi (2018), and hence, a user request to the data warehouses does not affect the other data systems. Data warehouses must be protected from any types of data breaches for security purposes as they contain very critical company data. Companies rely on data warehouses as the primary decision support tools through the provision of integrated and historical data Ezzedine et al.(2021). Data warehouses provide integrated and historical data to experts, management personnel, donors, and other partners who seek to establish the company stand based on the available integrated data. Data warehouses also serve low-level staff who rely on the integrated data to use their expertise in the company’s tactical operations. In summary, data warehouses act as a special purpose database that stores, processes, and presents strategic data from operational databases as well as other affiliate data sources.
Basic concepts
Scholars have come up with different definitions for the data warehouse. According to Gulzar (n.d), a data warehouse stores information that is changeable over time, integrated into company operations but is nonvolatile and applicable in decision-making processes. Visweswaran et al. (2019) note that data warehouses merge data from non-related sources such as a historical report, affiliate sources and permit structured access to the data using convectional queries. The data warehouse presents the data in the form of reports that are used by company staff to make critical decisions. On a different note, Serasinghe et al. (2021) defined a data warehouse as a summation of technologies and techniques that are jointly applied to provide regulations in accessing otherwise distributed unstructured strategic data in an organization. Cigánek (2019) argued that a data warehouse is a huge data repository in an organization formed by pulling many data marts together.
A data warehouse can be compared to a structured relational database that is made up of different related tables. In fact, a data warehouse is developed using the traditional relational database methodology in that different data sources are either accessed independently or as much as they are related to others Chou et al. (2018). for instance, in a financial institution, financial records and employee records merger at some point. The merging is similar to the foreign relationships in relational databases. Application programming interfaces access data stored in databases (API) calls. Users and applications call queries that are executed by database engines. Database results are produced and reported back to the user or application based on the requests received. Databases store data for future reference and are accessible to all kinds of users and employees. On the other hand, a data warehouse stores strategic data that is essential in planning and decision making and is most important to management personnel.
Companies rely on operational data to carry out their daily operations. This kind of data is so important that it affects the performance of company activities every day. Employees mainly utilize operational data to execute the company agenda and other essential processes and procedures. As a result, operational data is susceptible to change should the companies adopt new processes or procedures or effect changes to the existing ones (Moalla et al., 2017). These kinds of databases are designed to reduce any chances of redundancy and do not require large storage spaces (Ezzedine et al., 2021 ). on the other hand, a data warehouse is primarily designed, developed, and targets management staff and other decision-making personnel. Unlike operational databases, which do not store large amounts of historical data, data warehouses contain information lasting several years. It requires large storage capacities and stores data in two main forms: as summarized or detailed depending on the purpose of the data Khouri et al. (2017).
Elements of a data warehouse
A data warehouse is a complex engineering product and is comprised of several modules, each playing an essential part in the main goal. This section will approach a data warehouse using the bottom-up technique adopted by (Moalla et al.,2017).
At the lowest point, a data warehouse contains a data source. The sources are comprised of operational tools and systems tasked with data collection on all business transactions. Above the data sources lies the staging area, which is mainly used for storage. This section is a set of different tools that jointly work to remove redundancies, clean data, transform and combine data, store data, and avail the data for use in the entire warehouse. Due to the complexity of a data warehouse, its design is only carried out by experts and is best achieved using a user-centered design (Ezzedine et al., 2021). In the integration phase, engineers design different data marts, which as subsets of the data warehouse but contain data on specific operations. The different data marts are integrated to form the data warehouse. A complete data warehouse is viewable from different dimensions and contains different types of data. A presentation server provides physical means to store and access data. The dimensional model provides mechanisms for the maintenance of the warehouse. The maintenance could include the addition or removal of some of the warehouse modules (Ezzedine et al., 2021). The relational online analytical process (ROLAP) gives the warehouse characteristics similar to those of a conventional relational database. The warehouse metadata provides data about the warehouse but can not be used in any decision-making process. At the top of the warehouse are a set of data analytical applications and tools. In this data warehouse section, data is accessible via back-end applications, data modeling applications, querying tools and services, and business processes.
Features of data warehouse
Data warehouse contains extremely significant information upon which company decisions are built. As a result, a data warehouse acts as a one-stop shop for sourcing all data needed in running and managing a business organization. According to (Khouri et al. (2017), a data warehouse can be distinguished from other data storage systems by its distinct characteristics. The features include non-volatility, time-variant data, integrated, subject-centered, and large storage requirements.
The main feature of a data warehouse is integration. Usually, warehouses contain data collected from different sources, using different tools, and stored in different formats. The formats vary from text, media files such as images, audio and video files and documents. There are no standard rules for storing data in a warehouse, and hence, reporting tools take much time to process or summarize the data. For instance, the marital status of employees can be presented in either of the following ways. Firstly, the data can be presented as plain text, that is, “married,” “single,” divorced”… In other sources, exerts can use codes to represent the status, that is, 1,2,3… Processing this kind of data can be very complex unless the systems provide decoding data types.
Data warehouses are usually subject specif and focus on data such as sales, customers, or products. The data warehouse stores information according to staff needs. Hence, the data warehouse engineered for one company may vary from that designed for another company, even if the companies operate in the same domain. The third feature of the data warehouse is the time variation of the data stored due to the significance of the data; the warehouse stores data over long periods, which could date back to over 20 years (Vaisman & Zimányi, 2019). Lastly, a data warehouse is nonvolatile in that its contents do not change over time. Usually, the data warehouse contains historical data which does not need to be altered; hence, it remains nonvolatile (Visweswaran et al., 2021).
The conceptual design of a data warehouse
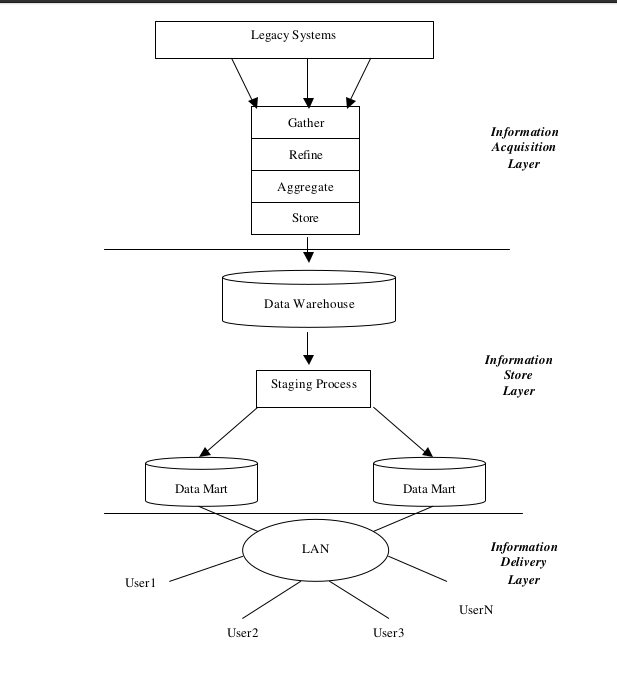
Data warehouses are designed to provide fast execution of user-generated queries. Hence., the data warehouse should be able to collect process and visual data effectively and within the shortest time possible. To store data in a data warehouse, organizations use legacy systems or perform a direct write on the data storage systems. The legacy systems include the most popular relational database vendors, such as Oracle and IBM (Visweswaran et al., 2021). once the data is collected and cleaned, it is stored in data marts that are more miniature versions of a data warehouse. Depending on the design concepts, data marts can either work independently or depend on other marts. The concept of interdependence is borrowed from table relationships in relational databases (ibid). Data marts are built with modularity in mind. This means engineers develop small independent or dependent data warehouses to achieve particular tasks. The different data marts are integrated to produce the overall warehouse, which supports the entire enterprise in its operations and decision-making processes. The conceptual design is summarized in the figure below.
Project Management
Project management is an essential task in the execution of any complex task. It ensures the final deliverable is availed on time and based on the accepted parameters. The data warehouse is a complex project and shall be executed by a team of five engineers, each playing a specific role. The table below represents the work breakdown structure for the project.
Requirement Analysis
Requirement analysis is an essential step in the software development life cycle. It helps developers understand user needs and business logic, putting them in a better position to deliver products in line with technological and user needs (Tria, Lefons & Tangorra, 2017 ). This section presents the requirement analysis process and the data sources used herein.
First, we studied the business model to establish the appropriate user types. Interviews and questionnaires were the main tools used in requirement gathering. The tools were also used to study the business model to help the engineers better understand the project under development. Next, a conceptual model of the company operations was created and mapped into a database model. the respective data types for various tables were also identified. Finally, the relationship between different database tables was established. The DW was developed, as illustrated in the figure below.
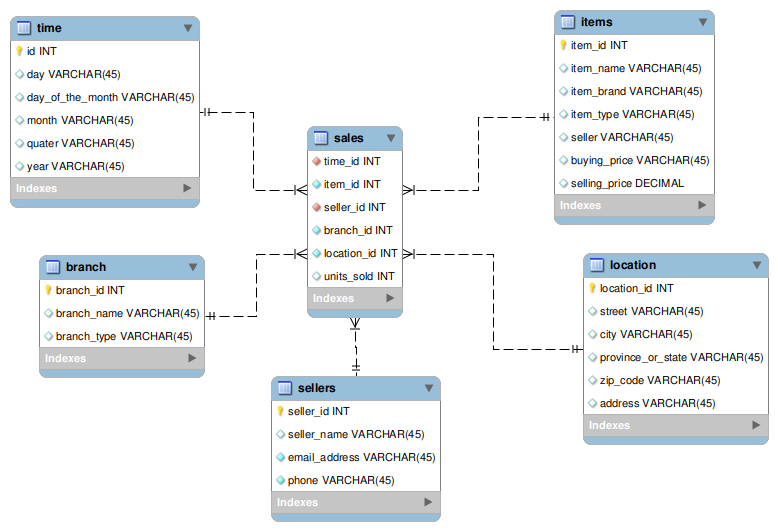
Data Model
The database model has one FACT table and five dimensional tables as shown in the figure below. The table “Sales” is the FACT table, while the rest are dimensional tables.
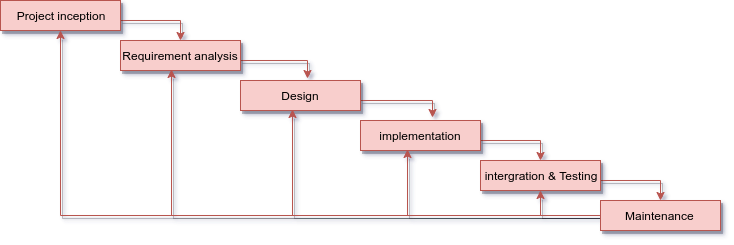
The DW was developed using the iterative waterfall model illustrated below. The iterative waterfall model is an improvement of the traditional waterfall model and gives engineers room to fix errors while the project is still under development.
Extract Transform and Load Data (ETL)
ETL is standard in warehouse management and has been around for a very long time. However, it is a complex process that entails collecting and processing data before it is loaded into the data warehouse. Such complex processes are resource-intensive and highly prone to errors that could compromise the integrity of the warehouse. Therefore, in the proposed model, data will be grouped into six main categories (the categories represent the tables in the database schema). Each category is discussed below.
- Time
The time data will be auto-generated every time a record is added to the table. Thus, the records will be depended on the time zone of the active user, that is, the one entering the data into the system. - Sellers
Seller data is an essential part of the warehouse. Sellers play a significant role in providing products and services to customers through the company’s eCommerce platform. Sellers will provide their names, phone numbers, and email addresses. In addition, they will be assigned unique identification numbers automatically. - Items
Items table plays a critical role in the DW. Every item record will provide information about its name, type, brand, cost, and projected selling price. In addition, the respective sellers will provide this information. Therefore, every item record will be associated with a seller. - Branches
Branches are owned by the company and will be the designated pickup stations. This information will be provided and can only be changed by the company employee. - Location
Location services are essential for all stakeholders. For example, the company will depend on location information to set up offices and pickup stations. In addition, sellers will depend on this information to target buyers, while buyers will utilize the resource to select the most convenient pickup stations. As a result, all will contribute to the entry, manipulation, and processing of location data. - Sales
This is the FACT table in the warehouse. It is associated with all other tables. Therefore, its data will depend on the contents of the other tables. as a result, integrity rules have been put in place to ensure high degrees of data integrity and availability.
Report Analysis
Unlike the traditional processing model, where different branches used different applications for data capturing and storage, the data warehouse was centralized and available to all. As a result, customers, sellers, and company officials upload and read data from the same storage, cutting the downtime needed to process data. For instance, an SQL query to insert location data will be the same for all users. The centralized data storage and processing technology is a significant boost to company operations. Besides, it provides the company with the proper business analysis tools that harness SQL analytics. The company decision-making processes will be improved as a result of the real-time processing capabilities brought about by the DW.
Conclusion
The proposed data warehouse will be a significant breakthrough for Infortrack in the future. The DW provides the company with a competitive advantage to thrive in the ever-changing market force. In addition, the DW solves the problem of using multiple technologies to process data that could otherwise be solved using one application. Although employees have different tastes for data analysis applications, the generated reports varied from branch to branch. Besides, the data types adopted by the branches differed. As a result, those at the company headquarters would struggle to reconstruct the data. With the current warehouse, users from different branches will enter similar data into the systems accessing the warehouse. As a result, data processing will be far much more straightforward at the end of the day than it was before.
However, the centralized data warehouse presents a big ethnological challenge. For example, if the servers hosting the DW fail, company operations will be grounded. This poses a significant threat to the continuity of company operations should such scenarios occur. Besides, the warehouse does not specify the front-end technologies that should be used to submit or retrieve data.
References
Chou, S. C., Yang, C. T., Jiang, F. C., & Chang, C. H. (2018). The implementation of a data-accessing platform built from big data warehouse of electric loads. In 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC) (Vol. 2, pp. 87-92). IEEE.
Cigánek, J. (2019). Design and Implementation of Open-data Data Warehouse. In 2019 6th International Conference on Advanced Control Circuits and Systems (ACCS) & 2019 5th International Conference on New Paradigms in Electronics & information Technology (PEIT) (pp. 185-190). IEEE.
Dabbèchi, H., Haddar, N. Z., Elghazel, H., & Haddar, K. (2020). Social Media Data Integration: From Data Lake to NoSQL Data Warehouse. In International Conference on Intelligent Systems Design and Applications (pp. 701-710). Springer, Cham.
Di Tria, F., Lefons, E., & Tangorra, F. (2017). Evaluation of data warehouse design methodologies in the context of big data. In International Conference on Big Data Analytics and Knowledge Discovery (pp. 3-18). Springer, Cham.
Ezzedine, S., Turki, S. Y., & Faiz, S. (2021). The Integration of Decision Maker’s Requirements to Develop a Spatial Data Warehouse.
Golfarelli, M., & Rizzi, S. (2018). From star schemas to big data: 20$$+ $$ years of data warehouse research. A comprehensive guide through the Italian database research over the last 25 years, 93-107.
Gulzar, A. Design and Implementation of an Enterprise Data Warehouse. n.d.
Khouri, S., Berkani, N., & Bellatreche, L. (2017). Tracing data warehouse design lifecycle semantically. Computer Standards & Interfaces, 51, 132-151.
Moalla, I., Nabli, A., Bouzguenda, L., & Hammami, M. (2017). Data warehouse design approaches from social media: review and comparison. Social Network Analysis and Mining, 7(1), 5.
Serasinghe, C. U., Jayakody, D. C. R., Dayananda, K. T. M. N., & Asanka, D. (2021). Design and Implementation of Data Warehouse for a Higher Educational Institute in Sri Lanka. In 2021 6th International Conference for Convergence in Technology (I2CT) (pp. 1-5). IEEE.
Vaisman, A., & Zimányi, E. (2019). Mobility data warehouses. ISPRS International Journal of Geo-Information, 8(4), 170.
Visweswaran, S., McLay, B., Capella, N., Morris, M., Milnes, J. T., Reis, S. E.,… & Becich, M. J. (2021). An Atomic Approach to the Design and Implementation of a Research Data Warehouse. medRxiv.