Introduction
Big Data tools refer to software used to process the entirety of computer information. As the multitude of data grew, so did the importance of technologies capable of working with such an amount of data. Hadoop resolved this problem by incorporating multiple data nodes, each of which processes a different type of data, such as e-mails, images, videos, and others. Processing results are then summed and aggregated into the final output. As a result, Hadoop can efficiently store and process vast amounts of data.
At the same time, Hadoop has a serious flow – it is not intended for the processing of small files. Hadoop’s specialty is big data sets, but small files are also generated in large quantities. Aggarwal, Verma, and Siwach (2021, p. 1) write that “a large number of small files also accounts to big data,” and Hadoop “doesn’t perform well when it comes to storing and processing huge number of small files.” The subsequent research question is as follows: considering the inevitability of small data accumulation, how can Hadoop handle small files, which are huge in figures, but small in size? The five tools chosen to illustrate the set of techniques and applications available within the framework are Hadoop Distributed File System, Hbase, Hive, Pig, and Mahout.
Tools
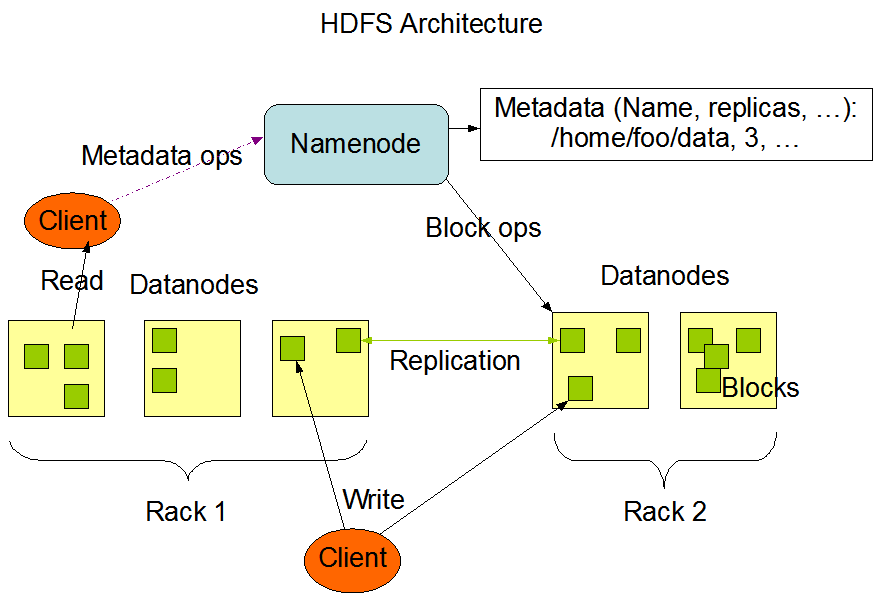
Handoop Distributed File System
Handoop Distributed File System (HDFS) is intended to retain very big data sets consistently and to deliver such data sets to user applications at high bandwidth. Thousands of machines in a big cluster host both directly associated storage and software duties (Anand, Vamsi, and Kumar, 2018). The resource may scale with demand while being cost-effective at all sizes (Ciritoglu et al., 2018; Zebaree et al., 2020). It is accomplished by dividing storage and computing among several servers.
HDFS Interface
HDFS makes Big Data easier to use because it allows the user to view Big Data as a structured entity. It is made possible by the use of data blocks. In essence, HDFS functions like Windows Explorer with blocks instead of folders. Although HDFS does not look like Explorer, its distribution of blocks and data nodes reminds it. All a user has to do is navigate through them.
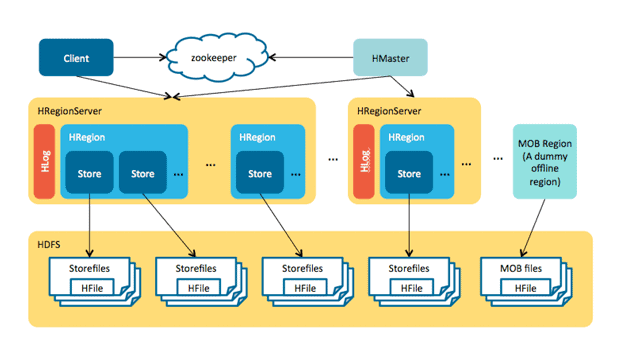
Hbase
Hbase is a column-based database management system built upon the structures of HDFS. Unlike relational database systems, HBase does not support a structured query language such as SQL. HBase facilitates the development of apps in Avro, REST, and Thrift (Saxena, Singh and Shakya, 2018). Hbase further automatizes the framework and increases its overall friendliness towards the users by making table sharding automatic and customizable, and introducing support for automatic failover between RegionServers.
Hbase Interface
HDFS makes Big Data easier to use because it adds vertical structure. Hbase utilizes column families, which allow users to create substructures. An appropriate way to conceptualize it is to image a table where each column contains information to all data units in this column. As a result, it becomes easier for a user to keep track of needed data by putting it in a corresponding table.
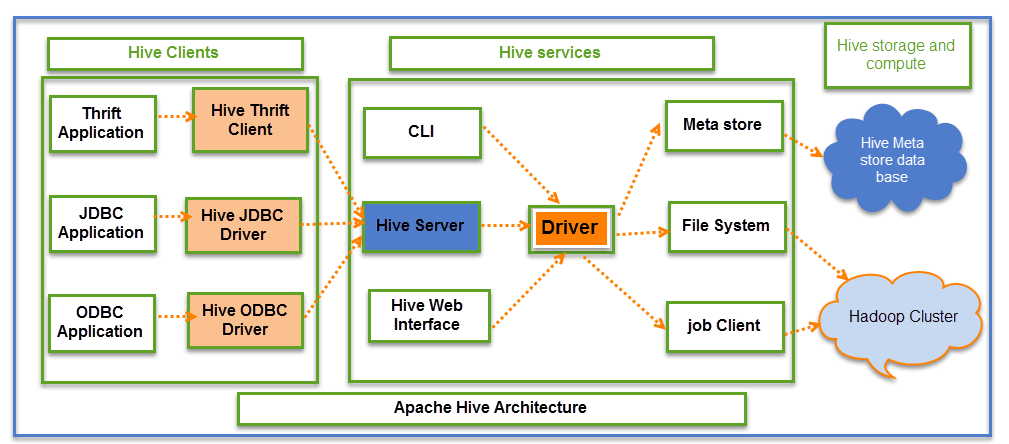
Hive
The Apache Hive provides a way for projecting structure onto this data and querying it using HiveQL, an SQL-like language. It erases the necessity to write Java in order to access data, thus making the interface friendlier. At the same time, this language allows conventional map/reduce programmers to insert in their bespoke mappers and suppressants when expressing this logic in HiveQL is difficult or wasteful (Hussain, Sanga and Mongia, 2019). Metadata is stored in an RDBMS, which considerably reduces the time required to execute semantic tests during query execution (Kaur, Chauhan and Mittal, 2018). Hive allows users to utilize SQL to read, write, and manage petabytes of data, allowing regular users to engage in the majority of the big data operations.
Hive Interface
HDFS makes Big Data easier to use because it does not necessitate the use of SQL. In order for a user to analyse data set with SQL, they have to input a SQL query to extract data. When a user uses Hive, they have to write SQL-like queries, which are automatically converted by Hive. As a result, extracting data takes much less time and does not necessitate the use of SQL.
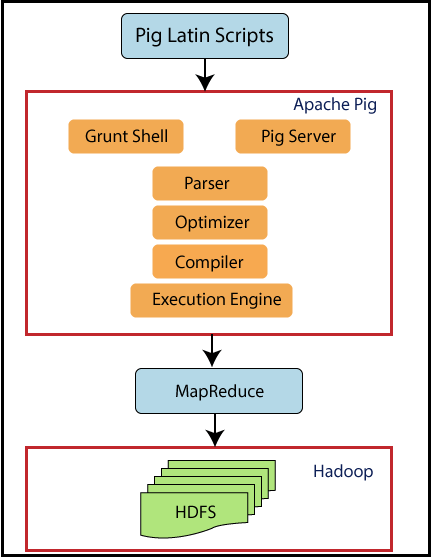
Pig
Pig is a data analysis platform that incorporates a high-level language for writing data analysis algorithms and infrastructure for assessing these programs. Pig’s infrastructure layer now consists of a translator that generates sequences of Map-Reduce programs, for which large-scale parallel implementations already exist (Priyanka et al., 2021). Pig makes it easy to execute simple, mostly parallel data analysis tasks, often presented by the previously discussed tools (Kaur, Chauhan and Mittal, 2018). Complex operations involving several interconnected data transformations are clearly represented as data flow sequences, making them simple to design, comprehend, and manage.
Pig Interface
In a similar way to Hive, Pig makes Big Data easier to use because it bypasses SQL. However, unlike Hive, Pig can work with semi-structured and unstructured data, whereas Hive is limited to structured data. Everything else is extremely similar to Hive – a user inputs scripts, which automatically access raw data. Once again, SQL is bypassed with no loss of time, as there are no further SQL queries necessary.
Mahout
Hadoop Apache Mahout is a scalable machine-learning algorithm library built on top of Apache Hadoop and the MapReduce architecture. It comprises collaborative filtering, clustering, and classification tools (Dulhare and Gouse, 2020). Mahout facilitates work with Big Data since it only requires the user to create a learning algorithm based on user behavior. Collaborative filtering analyzes user activity and recommends products, including Amazon suggestions. Clustering puts objects in a certain class (such as web pages or newspaper articles) into naturally occurring groups, so that items in the same category are similar to each other. Classification learns from previous categorizations and then allocates unclassified things to the most appropriate category, presenting a well-structured and user-friendly tool.
Mahout Interface
Mahout makes Big Data easier to use because it lifts the necessity to analyse other users’ preferences from programmers. Instead, a programmer inputs an algorithm, which is then used to automatically analyse customers’ preferences, classify them and issue recommendations. In essence, a programmer teaches the engine to recognize certain types of data instead of manually inputting them. Without Mahout, making personalized ads and recommendations would take incomprehensibly more time.
Integration of Tools
In conjunction, the tools outlined above, as well as the other instruments present within Hadoop, form an ecosystem that allows companies to simplify Big Data. HDFS provides a file system for other tools to operate in, while Hive and Pig organize and process different queries on various programming languages within HIDS (Wakde et al., 2018). Mahout enables the clustering mechanism that increases the overall framework resilience, and HBase acts as the middle element between HDFS interface and other tools. Furthermore, HDFS operates as a key tool for all further analyses of the large volumes of data carried out trough different instruments. It provides a supporting infrastructure, operating with petabytes and zettabytes of information units. Hive and Pig are frequently interchangeable with other similar processing tools, with key differences lying in programming languages they are the most compatible with.
Existing Research
The existing research covers the history and capabilities of Hadoop framework. It was designed by Mike Carafella and Doug Cutting in 2005, and was originally meant to support and further develop a search engine (Allam, 2018). Geographically, the tool itself was developed in the United States. However, currently the platform is used to assist advanced analytics projects such as predictive analytics, data mining, and machine learning applications. For example, Hadoop substantially facilitated data analysis by presenting data in the form of graphs (Garg, 2021).
The main quality of Hadoop’s interface that allows for versatility and increases the usability of big data lies in its flexibility and ability to be scalable. If the situation requires, an established network can be expanded with the addition of new servers with no barrier of the data storage size, since the principle of distribution lies at the core of the framework (Bukhari, Park, and Shin, 2018). The cluster-like nature of the tools and information processing ensures that if one element in the chain gets damaged, a back-up cluster is available (Sharma et al., 2018). Over the last few years Hadoop has become increasingly present in the data management departments across businesses, with notable examples including Amazon Web Services, Marks & Spencer, and British Airways (Rathor, 2021). Due to the overall resilience of the framework, it is likely, that its popularity will continue to increase with time.
Conclusion
In conclusion, Big Data tools, such as HDMS, Hbase, Hive, Pig, and Mahout facilitate work with Big Data, make it fast and secure. However, Hadoop framework does not resolve the problem of a large number of small files. The problem of gradual accumulation of small files is acknowledged by the scientific community, yet it remains unresolved (Masadeh, Azmi, and Ahmad, 2020). One possible solution is to introduce “metadata management in HDFS clusters for small files” (Aggarwal, Verma, and Siwach, p. 10). However, given the Big Data orientation of Hadoop, there is no current evidence that such an approach will succeed. Further research should therefore focus on studying and implementing metadata management optimization, which will help tackle the problem of the growing mass of small files, which Hadoop will not be able to handle.
Reference List
Aggarwal, R., Verma, J. and Siwach, M. (2021) ‘Small files’ problem in Hadoop: A systematic literature review’, Journal of King Saud University-Computer and Information Sciences. pp.1-15.
Allam, S. (2018) ‘An exploratory survey of Hadoop log analysis tools’, International Journal of Creative Research Thoughts (IJCRT), 75(18), pp.2320-2882. Web.
Anand, P.M., Vamsi, G.S. and Kumar, P.R. (2018) ‘A novel approach for insight finding mechanism on clickstream data using Hadoop’, 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), The Institute of Electrical and Electronics Engineers, Coimbatore, India, IEEE, pp. 446-449.
Bukhari, S.S., Park, J. and Shin, D.R. (2018) ‘Hadoop based demography big data management system’, 2018 19th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), The Institute of Electrical and Electronics Engineers, Busan, Korea, IEEE., pp. 93-98.
Ciritoglu, H. E. et al. (2018) ‘Investigation of replication factor for performance enhancement in the hadoop distributed file system’, Companion of the 2018 ACM/SPEC International Conference on Performance Engineering. pp. 135-140.
Dulhare, U.N. and Gouse, S. (2020) ‘Hands on Mahout—machine learning tool’, Machine Learning and Big Data: Concepts, Algorithms, Tools and Applications, pp.361-421.
Garg, U. (2000) ‘Data analytic models that redress the limitations of MapReduce’, International Journal of Web-Based Learning and Teaching Technologies, 16(6), pp.1-15.
Masadeh, M.B., Azmi, M.S. and Ahmad, S.S.S. (2020) ‘Available techniques in hadoop small file issue, International Journal of Electrical and Computer Engineering’, 10(2), pp.2097-2101.
Saxena, A., Singh, S. and Shakya, C. (2018) ‘Concepts of HBase archetypes in big data engineering’, Big Data in Engineering Applications, pp. 83-111.
Sharma, I., et al. (2018) ‘Analysis of mahout big data clustering algorithms’, Intelligent Communication, Control and Devices.
Hussain, T., Sanga, A., and Mongia, S. (2019) ‘Big Data Hadoop tools and technologies: A review’, Proceedings of International Conference on Advancements in Computing & Management (ICACM). Jagah Nath University, Jaipur, India, pp. 574-578.
Kaur, R., Chauhan, V. and Mittal, U. (2018) ‘Metamorphosis of data (small to big) and the comparative study of techniques (HADOOP, HIVE and PIG) to handle big data’, International Journal of Engineering & Technology, 7(2.27), pp.1-6. Web.
Priyanka, et al. (2021) ‘Big data technologies with computational model computing using hadoop with scheduling challenges’, Deep Learning and Big Data for Intelligent Transportation, 3-19.
Rathor, S. (2021) ‘Use of Hadoop for Sentiment Analysis on Twitter’s Big Data’, Smart Innovations in Communication and Computational Sciences, pp. 47-53.
Wakde, A., et al. (2018) ‘Comparative analysis of Hadoop tools and spark technology’, 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), IEEE, Pune, India, pp. 1-4. IEEE.
Yue, H. (2018) Design of HBase and hybrid Hadoop ecosystem architecture in transportation data management. Web.